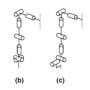
A scene from a demonstration video that simulates the experiment. Credit: Ozaki et al.
Researchers at NTT Corporation in Japan have recently developed a user-centered reinforcement learning approach that could be used to teach 'manners' to social robots. Their method, outlined in a paper pre-published on arXiv, allows a robot to greet or attract the attention of passersby without causing them discomfort.
"My idea was inspired by barkers in a marketplace," Yasunori Ozaki, one of the researchers who carried out the study, told TechXplore. "Most barkers call passersby that are interested in the restaurant, yet they hardly call the others. As a result of this observation, I came up with the following hypothesis: barkers determine what passersby to call by inferring their interest in the service they are advertising from their behavior. I wanted to develop a method that allows a robot to imitate a barker's actions, by training it to understand people's interests."
Social robots are gradually entering a variety of fields, including healthcare and retail. In retail, for instance, social robots could help to explain products to passersby and potential customers.
Recently, a growing number of companies have started testing the effectiveness of robots as customer service agents, such as receptionists, guides or exhibitors. To be most effective in customer-facing roles, however, robots would need to greet passersby without startling them or making them feel uncomfortable.
With this in mind, Ozaki and his colleagues set out to develop a method that allows robots to adapt their mannerisms according to the situation they are in and the person with whom they are interacting. Their approach employs user-centered reinforcement learning to analyze data collected by a robot's sensors, so that it can adapt its actions accordingly.

The experimental environment. Credit: Ozaki et al.
"My method allows a robot to learn actions by observing the reactions of passersby," Ozaki explained. "When a robot acts towards a passerby, the passerby typically responds to such action. For example, if a robot calls a passerby, the call could cause that the passerby discomfort, or may result in the passerby becoming interested in the robot. The robot estimates a passerby's feelings from his/her reactions, by analyzing footage gathered by a sensor placed at its back."
The approach devised by Ozaki and his colleagues is based on a reward and penalty scheme. If the robot infers discomfort in any passersby that it is communicating with, it gets a penalty. On the other hand, if a passerby stops, interacts with the robot and gets interested in it, the robot receives a reward. Over time, the robot learns to adapt its interaction strategies in order to gain people's attention without making potential customers feel uncomfortable.
"My method allows a robot to find combinations of actions that do not cause discomfort to passersby," Ozaki said. "Many researchers have examined user experience (UX), including discomfort, in human-robot interactions. However, they did not train robots based on this UX. I believe that we need to teach robots some manners related to UX and the human world. This would then allow the robot to tailor its actions to different situations and users, based on the manners it has acquired."
To evaluate their method, the researchers carried out an experiment at an office entrance, in which a small social robot called out to passersby and tried to attract their attention. Their findings were highly promising, as in most cases, the robot was able to attract people's attention without causing them discomfort.
The approach devised by Ozaki and his colleagues is designed to improve robot interactions with individual passersby, rather than with a bigger group of people. Further studies could expand the model to enhance the robot's interactions with groups of people as well. In addition, the researchers are planning to evaluate their method in scenarios where the social robot covers other roles, for instance that of a salesperson.
More information: Can robot attract passersby without causing discomfort by user-centered reinforcement learning? arXiv:1903.05881 [cs.AI]. arxiv.org/abs/1903.05881
© 2019 Science X Network