Soldiers could teach future robots how to outperform humans

In the future, a soldier and a game controller may be all that's needed to teach robots how to outdrive humans.
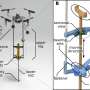
At the U.S. Army Combat Capabilities Development Command's Army Research Laboratory and the University of Texas at Austin, researchers designed an algorithm that allows an autonomous ground vehicle to improve its existing navigation systems by watching a human drive. The team tested its approach—called adaptive planner parameter learning from demonstration, or APPLD—on one of the Army's experimental autonomous ground vehicles.
"Using approaches like APPLD, current soldiers in existing training facilities will be able to contribute to improvements in autonomous systems simply by operating their vehicles as normal," said Army researcher Dr. Garrett Warnell. "Techniques like these will be an important contribution to the Army's plans to design and field next-generation combat vehicles that are equipped to navigate autonomously in off-road deployment environments."
The researchers fused machine learning from demonstration algorithms and more classical autonomous navigation systems. Rather than replacing a classical system altogether, APPLD learns how to tune the existing system to behave more like the human demonstration. This paradigm allows for the deployed system to retain all the benefits of classical navigation systems—such as optimality, explainability and safety—while also allowing the system to be flexible and adaptable to new environments, Warnell said.
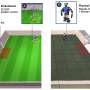
"A single demonstration of human driving, provided using an everyday Xbox wireless controller, allowed APPLD to learn how to tune the vehicle's existing autonomous navigation system differently depending on the particular local environment," Warnell said. "For example, when in a tight corridor, the human driver slowed down and drove carefully. After observing this behavior, the autonomous system learned to also reduce its maximum speed and increase its computation budget in similar environments. This ultimately allowed the vehicle to successfully navigate autonomously in other tight corridors where it had previously failed."
This research is part of the Army's Open Campus initiative, through which Army scientists in Texas collaborate with academic partners at UT Austin.
"APPLD is yet another example of a growing stream of research results that has been facilitated by the unique collaboration arrangement between UT Austin and the Army Research Lab," said Dr. Peter Stone, professor and chair of the Robotics Consortium at UT Austin. "By having Dr. Warnell embedded at UT Austin full-time, we are able to quickly identify and tackle research problems that are both cutting-edge scientific advances and also immediately relevant to the Army."
The team's experiments showed that, after training, the APPLD system was able to navigate the test environments more quickly and with fewer failures than with the classical system. Additionally, the trained APPLD system often navigated the environment faster than the human who trained it. The peer-reviewed journal, IEEE Robotics and Automation Letters, published the team's work: APPLD: Adaptive Planner Parameter Learning From Demonstration .
"From a machine learning perspective, APPLD contrasts with so called end-to-end learning systems that attempt to learn the entire navigation system from scratch," Stone said. "These approaches tend to require a lot of data and may lead to behaviors that are neither safe nor robust. APPLD leverages the parts of the control system that have been carefully engineered, while focusing its machine learning effort on the parameter tuning process, which is often done based on a single person's intuition."
APPLD represents a new paradigm in which people without expert-level knowledge in robotics can help train and improve autonomous vehicle navigation in a variety of environments. Rather than small teams of engineers trying to manually tune navigation systems in a small number of test environments, a virtually unlimited number of users would be able to provide the system the data it needs to tune itself to an unlimited number of environments.
"Current autonomous navigation systems typically must be re-tuned by hand for each new deployment environment," said Army researcher Dr. Jonathan Fink. "This process is extremely difficult—it must be done by someone with extensive training in robotics, and it requires a lot of trial and error until the right systems settings can be found. In contrast, APPLD tunes the system automatically by watching a human drive the system—something that anyone can do if they have experience with a video game controller. During deployment, APPLD also allows the system to re-tune itself in real-time as the environment changes."
The Army's focus on modernizing the Next Generation Combat Vehicle includes designing both optionally manned fighting vehicles and robotic combat vehicles that can navigate autonomously in off-road deployment environments. While soldiers can navigate these environments driving current combat vehicles, the environments remain too challenging for state-of-the-art autonomous navigation systems. APPLD and similar approaches provide a new potential way for the Army to improve existing autonomous navigation capabilities.
"In addition to the immediate relevance to the Army, APPLD also creates the opportunity to bridge the gap between traditional engineering approaches and emerging machine learning techniques, to create robust, adaptive, and versatile mobile robots in the real-world," said Dr. Xuesu Xiao, a postdoctoral researcher at UT Austin and lead author of the paper.
To continue this research, the team will test the APPLD system in a variety of outdoor environments, employ soldier drivers, and experiment with a wider variety of existing autonomous navigation approaches. Additionally, the researchers will investigate whether including additional sensor information such as camera images can lead to learning more complex behaviors such as tuning the navigation system to operate under varying conditions, such as on different terrain or with other objects present.
More information: Xuesu Xiao et al, APPLD: Adaptive Planner Parameter Learning From Demonstration, IEEE Robotics and Automation Letters (2020). DOI: 10.1109/LRA.2020.3002217