New technology exploits fluorescence and machine learning to speedily scan thousands of images

Any biological sample—dirt, water, or food, for example—contains billions of bacteria. Only a few are harmful to humans, or pathogenic. But those few pathogens can mean the difference between a reliable supply of meat or lettuce, for example, and an outbreak of food poisoning—or worse, a pandemic.
Discovering deadly pathogens before they strike is one goal of the Defense Advanced Research Projects Agency (DARPA). The agency, part of the U.S. Department of Defense, works on developing new technologies to help protect the United States.
A few years ago, DARPA issued a "Friend or Foe" challenge to the research community to see if they could quickly isolate pathogens from a very complicated sample without affecting the sample's basic functionality, or phenotype. One of three institutions rising to the challenge, Pacific Northwest National Laboratory (PNNL) formed a multidisciplinary team with scientific expertise in soil microbiology and proteomics, biochemical synthesis, and data analytics.
Now, midway through a project that started in 2019, the team is refining a promising new method they developed for pathogen discovery.
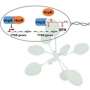
The method, called OmniScreen, is an end-to-end pipeline for quickly and effectively distinguishing a plethora of pathogenic cells in a microbial community. The system extracts, probes, and screens thousands of cells to pick out pathogens in a matter of days.
Notably, OmniScreen also keeps the samples alive.
Typically, in biological research, a sample is frozen and then "fixed" as needed for use. The fixing solution can kill the bacteria, or at least alter its original phenotype. Overcoming this obstacle was critical for PNNL to get the green light from DARPA for the next phase of their project.
"We really weren't sure it was going to work. Part of the risk we identified at the start was that cells might not survive the probing," said Becky Hess, a biomedical scientist at PNNL and the project lead for OmniScreen. "That was one of the criteria for moving to phase two—and we made it work."

Priming the bacteria pipeline
The first challenge was to extract bacteria hidden away in tiny pockets of a soil sample. Led by microbiologist and Laboratory Fellow Janet Jansson, the team tried a few different centrifugation techniques and settled on density gradients. After the sample spun in a neutral solution, the heavy soil particles settled to the bottom and the lighter bacteria floated to the top.
The technique initially yielded one million cells in three hours—two hours longer than the team's initial goal, which they continue to work toward. Jansson emphasized the need for speed in extraction and analytical techniques for DARPA.
Next, Jansson sorted the live cells from the dead ones and stained them to help with identification during subsequent phenotyping. This proteomic analysis took place at the Environmental Molecular Sciences Laboratory (EMSL), a U.S. Department of Energy Office of Science user facility located on the PNNL-Richland campus. Powerful mass spectrometers at EMSL mapped the traits associated with proteins in each cell.
Comparisons of subsamples before and after the proteomics step confirmed the phenotypes still matched. To keep the cells alive and the phenotype for each cell intact, Jansson came up with a simple but novel maintenance media—soil tea.
"When we steep the soil in water for the centrifuge step, we end up with a kind of tea," explained Jansson. "It works perfectly to keep the cells from going into shock in a new environment."
Baiting and binning the pathogens
Bacteria are a type of microbe that can contain specific features, or chemistry, that make them pathogenic. Wright uses information about microbial features to build chemical probes with similar molecular traits. The probes serve as bait to catch bacteria with an affinity for the same traits.
"Like a fish on a hook, once the microbe grabs a probe, that's it—they're stuck," said Aaron Wright, a biomedical scientist in PNNL's Biological Sciences Division. Wright added that different colors on the probes give them away. "We know which fish we caught."
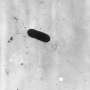
 or showed signs of damage (right)—indicating the presence of a pathogen. Credit: Becky Hess | Pacific Northwest National Laboratory")
Also built into each probe is a reporter mechanism for tracking purposes. In this case, that mechanism is fluorescence. Once a probe becomes stuck to a protein, it glows a certain color depending on the pathogen.
Wright then uses a flow cytometer to sort the bacteria one cell at a time at a rate of more than 10 million cells per hour. The instrument can tell if the cell has a colored probe, and therefore pathogenic features (or not), and bins them accordingly.
"We can create all sorts of bait to hook different types of pathogens," said Wright.
In the laboratory, the technique is called multiplexing; multiple probes can quickly and simultaneously target multiple pathogenic traits.
Screening for sick cells
Once probed, the bacteria hang out in a plastic petri dish along with human lung, gut, and immune cells. The team uses lung and gut cells because they are the most common routes for infection in humans. Under a standard microscope, healthy growing cells are seen to adhere strongly to the dish, but sickly cells lose structural integrity and start to lift away from the dish.
"Pathogens can evade immune cells and cause lung or gut tissue damage," said Hess. "When the cell junctions start falling apart, that's an indication of pathogen exposure."
The damaged cells also glow.
"This is our validation step," said Hess. "If the human cells look healthy, no pathogens are present. If the human cells lose structural integrity or glow, that tells us a pathogen is introduced."
But that validation is a time-consuming and unwieldy step. Hess said one assay can yield 15,000 images. Even with an automated imaging microscope, it still took days to determine pathogenicity by manually reviewing all the images. This hurdle is where machine learning—the third segment of the pipeline—comes in.

Machine learning speeds pathogen discovery
Enoch Yeung, an assistant professor at the University of California, Santa Barbara, developed the machine learning algorithm to recognize cellular features that indicate sick versus healthy cells.
Yeung conceived the OmniScreen idea for the "Friend or Foe" challenge while working on other research as a visiting scientist in PNNL's National Security Directorate. Aware of Hess's expertise in immunology and synthetic biology, he asked her, "Can you make human cells tell you if they're sick?" She said, "Yes, I can."
The two scientists looked through her collection of healthy versus unhealthy cells to build a sparse, labeled dataset to train the algorithm. Learning from those images and the color—or phenotype—of the pathogen, the algorithm quickly screened thousands of images and generated data plots with three s-shaped curves: healthy cells crashing (dying), unhealthy cells increasing, and the growth rate of bacteria colonies. The steeper the curve on the left side of the plot, the more aggressive the pathogen.
Ramping up throughput
In phase one tests, the OmniScreen algorithm resolved 30 species of bacteria with 92 percent accuracy in one week. The ground truth sample provided by DARPA contained 19 pathogenic bacteria; OmniScreen found 17—much better than expected.
Entering phase two of the $8.4 million project, the team's next challenge is to resolve a sample containing nearly twice the number of bacteria as in the soil sample—but from an unknown source.
As in phase one, Robert Egbert, a synthetic biologist, focuses on tackling the critical integration of instruments and process steps across the system.
"We're continually working on handoffs between the technical areas," said Hess, "but having a blind sample is a true test of the system."