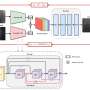
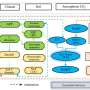
Overview of the proposed method. Credit: XIOPM
A research team led by Prof. Lu Xiaoqiang from the Xi'an Institute of Optics and Precision Mechanics (XIOPM) of the Chinese Academy of Sciences proposed a novel mutual attention inception network (MAIN) and a dataset named RSIVQA for remote sensing visual question answering. The results were published in IEEE Transactions on Geoscience and Remote Sensing.
Remote sensing visual question answering (VQA) mainly aims at making semantic understanding of remote sensing images (RSIs) objective and interactive. Specifically, given an RSI, an intelligent agent will answer a question about the remote sensing scene.
Most of the existing methods ignore the spatial information of RSIs and word-level semantic information of questions, which restricts their applications in many complex scenes.
Accordingly, in this study, the proposed MAIN was made up of two parts, including the representation module and the fusion module. The representation module was devised to obtain the features of image and question which can provide better representations.
As for the fusion module, it enhanced the discriminative ability of representations which can acquire correct answers by reinforcing the representations of image and question.
According to the experiments results, the proposed method can capture the alignments between images and questions under different evaluation metrics. This study provides a new perspective for the remote sensing visual question answering.
More information: Xiangtao Zheng et al, Mutual Attention Inception Network for Remote Sensing Visual Question Answering, IEEE Transactions on Geoscience and Remote Sensing (2021). DOI: 10.1109/TGRS.2021.3079918
Provided by Chinese Academy of Sciences