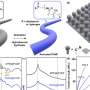
Meta-Semi trains deep networks using pseudo-labeled samples whose gradient directions are similar to labeled samples. Algorithm 1 shows the Meta Semi pseudo code. The Meta-Semi algorithm outperforms state-of-the-art semi-supervised learning algorithms. Credit: CAAI Artificial Intelligence Research, Tsinghua University Press
Deep learning based semi-supervised learning algorithms have shown promising results in recent years. However, they are not yet practical in real semi-supervised learning scenarios, such as medical image processing, hyper-spectral image classification, network traffic recognition, and document recognition.
In these types of scenarios, the labeled data is scarce for hyper-parameter search, because they introduce multiple tunable hyper-parameters. A research team has proposed a novel meta-learning based semi-supervised learning algorithm called Meta-Semi, that requires tuning only one additional hyper-parameter. Their Meta-Semi approach outperforms state-of-the-art semi-supervised learning algorithms.
The team published their work in the journal CAAI Artificial Intelligence Research.
Deep learning, a machine learning technique where computers learn by example, is showing success in supervised tasks. However, the process of data labeling, where the raw data is identified and labeled, is time-consuming and costly. Deep learning in supervised tasks can be successful when there is plenty of annotated training data available. Yet in many real-world applications, only a small subset of all the available training data are associated with labels.
"The recent success of deep learning in supervised tasks is fueled by abundant annotated training data," said Gao Huang, associate professor with the Department of Automation at Tsinghua University. However, the time-consuming, costly collection of precise labels is a challenge researchers have to overcome. "Meta-semi, as a state-of-the-art semi-supervised learning approach, can effectively train deep models with a small number of labeled samples," said Huang.
With the research team's Meta-Semi classification algorithm, they efficiently exploit the labeled data, while requiring only one additional hyper-parameter to achieve impressive performance under various conditions. In machine learning, a hyper-parameter is a parameter whose value can be used to direct the learning process.
"Most deep learning based semi-supervised learning algorithms introduce multiple tunable hyper-parameters, making them less practical in real semi-supervised learning scenarios where the labeled data is scarce for extensive hyper-parameter search," said Huang.
The team developed their algorithm working from the assumption that the network could be trained effectively with the correctly pseudo-labeled unannotated samples. First they generated soft pseudo labels for the unlabeled data online during the training process based on the network predictions.
Then they filtered out the samples whose pseudo labels were incorrect or unreliable and trained the model using the remaining data with relatively reliable pseudo labels. Their process naturally yielded a meta-learning formulation where the correctly pseudo-labeled data had a similar distribution to the labeled data. In their process, if the network is trained with the pseudo-labeled data, the final loss on the labeled data should be minimized as well.
The team's Meta-Semi algorithm achieved competitive performance under various conditions of semi-supervised learning. "Empirically, Meta-Semi outperforms state-of-the-art semi-supervised learning algorithms significantly on the challenging semi-supervised CIFAR-100 and STL-10 tasks, and achieves competitive performance on CIFAR-10 and SVHN," said Huang.
CIFAR-10, STL-10, and SVHN are datasets, or collections of images, that are frequently used in training machine learning algorithms. "We also show theoretically that Meta-Semi converges to the stationary point of the loss function on labeled data under mild conditions," said Huang. Compared to existing deep semi-supervised learning algorithms, Meta-Semi requires much less effort for tuning hyper-parameters, but achieves state-of-the-art performance on the four competitive datasets.
Looking ahead to future work, the research team's aim is to develop an effective, practical and robust semi-supervised learning algorithm. "The algorithm should require a minimal number of data annotations, minimal efforts of hyper-parameter tuning, and a minimized training time. To attain this goal, our future work may focus on reducing the training cost of Meta-Semi," said Huang.
More information: Yulin Wang et al, Meta-Semi: A Meta-Learning Approach for Semi-Supervised Learning, CAAI Artificial Intelligence Research (2023). DOI: 10.26599/AIR.2022.9150011
Provided by Tsinghua University Press