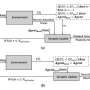
For every pair of objects, the researchers feed their features into a relation encoder to get relation rij and object i’s state sobji. (Top Left) Using the greedy method, for each object, they find the maximum Q value to get our focus object, relation object, and action. (Top Right) Once they gathered their focus object and relation object, they feed their states and all of their relations to their decoders to predict the change in position and change in velocity. Credit: Choi & Yoon.")
A detailed diagram of the approach developed by the researchers. (Bottom right) For every pair of objects, the researchers feed their features into a relation encoder to get relation rij and object i’s state sobji. (Top Left) Using the greedy method, for each object, they find the maximum Q value to get our focus object, relation object, and action. (Top Right) Once they gathered their focus object and relation object, they feed their states and all of their relations to their decoders to predict the change in position and change in velocity. Credit: Choi & Yoon.
From their first years of life, human beings have the innate ability to learn continuously and build mental models of the world, simply by observing and interacting with things or people in their surroundings. Cognitive psychology studies suggest that humans make extensive use of this previously acquired knowledge, particularly when they encounter new situations or when making decisions.
Despite the significant recent advances in the field of artificial intelligence (AI), most virtual agents still require hundreds of hours of training to achieve human-level performance in several tasks, while humans can learn how to complete these tasks in a few hours or less. Recent studies have highlighted two key contributors to humans' ability to acquire knowledge so quickly—namely, intuitive physics and intuitive psychology.
These intuition models, which have been observed in humans from early stages of development, might be the core facilitators of future learning. Based on this idea, researchers at the Korea Advanced Institute of Science and Technology (KAIST) have recently developed an intrinsic reward normalization method that allows AI agents to select actions that most improve their intuition models. In their paper, pre-published on arXiv, the researchers specifically proposed a graphical physics network integrated with deep reinforcement learning inspired by the learning behavior observed in human infants.
"Imagine human infants in a room with toys lying around at a reachable distance," the researchers explain in their paper. "They are constantly grabbing, throwing and performing actions on objects; sometimes, they observe the aftermath of their actions, but sometimes, they lose interest and move on to a different object. The 'child as a scientist' view suggests that human infants are intrinsically motivated to conduct their own experiments, discover more information, and eventually learn to distinguish different objects and create richer internal representations of them."
Psychology studies suggest that in their first years of life, humans are continuously experimenting with their surroundings, and this allows them to form a key understanding of the world. Moreover, when children observe outcomes that do not meet their prior expectations, which is known as expectancy violation, they are often encouraged to experiment further to achieve a better understanding of the situation they're in.
The team of researchers at KAIST tried to reproduce these behaviors in AI agents using a reinforcement-learning approach. In their study, they first introduced a graphical physics network that can extract physical relationships between objects and predict their subsequent behaviors in a 3-D environment. Subsequently, they integrated this network with a deep-reinforcement learning model, introducing an intrinsic reward normalization technique that encourages an AI agent to explore and identify actions that will continuously improve its intuition model.
Using a 3-D physics engine, the researchers demonstrated that their graphical physics network can efficiently infer the positions and velocities of different objects. They also found that their approach allowed the deep reinforcement learning network to continuously improve its intuition model, encouraging it to interact with objects solely based on intrinsic motivation.
In a series of evaluations, the new technique devised by this team of researchers achieved remarkable accuracy, with the AI agent performing a greater number of different exploratory actions. In the future, it could inform the development of machine learning tools that can learn from their past experiences faster and more effectively.
"We have tested our network on both stationary and non-stationary problems in various scenes with spherical objects with varying masses and radii," the researchers explain in their paper. "Our hope is that these pre-trained intuition models will later be used as a prior knowledge for other goal-oriented task such as ATARI games or video prediction."
More information: Intrinsic motivation driven intuitive physics learning using deep reinforcement learning with intrinsic reward normalization. arXiv:1907.03116 [cs.LG]. arxiv.org/abs/1907.03116
© 2019 Science X Network