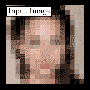This AI turns blurry pixelated photos into hyperrealistic portraits that look like real people. The system automatically increases any image's resolution up to 64x, ‘imagining’ features such as pores and eyelashes that weren’t there in the first place. Credit: Duke University
A photo editing tool designed by a programming team at Duke University in Durham, North Carolina, raises prospects for sharper, cleaner images in digital presentations and also promises hours of fun for older-video game fans who can now generate crystal clear faces for low-pixel characters who populated early products. But the tool also unexpectedly brought to the surface concerns about bias in the use of datasets in massive machine learning projects.
PULSE, Photo Upsampling via Latent Space Exploration, was created by Duke researchers to create more realistic images from low-pixel source data. In their research paper distributed earlier this year, the team explained how their approach differed from earlier efforts to generate lifelike images from 8-bit imagery.
"Instead of starting with the low resolution image and slowly adding detail, PULSE traverses the high-resolution natural image manifold, searching for images that downscale to the original low resolution image," the report stated.
That means their algorithm for constructing lifelike faces draws from massive datasets of images of real people.
The PULSE system can convert a 16 pixel x 16 pixel image into a 1024 pixel by 1024 pixel image in seconds.
Along with their findings, the team uploaded PULSE to GitHub and encouraged experimentation.
Denis Malimonov, a Russian developer, built and distributed his own app last week called Face Depixelizer. Response on Twitter was immediate as users uploaded their own results of often humorous representations of characters from classic games such as Steve and a Creeper from Minecraft, Mario from Super Mario, and Link from Legend of Zelda.
The Duke team acknowledges the entertainment value of PULSE, but notes that it should prove useful, practically and economically, in an era of greater degrees of exploration and research.
"In this work, we aim to transform blurry, low-resolution images into sharp, realistic, high-resolution images," the report said. "In many areas … sharp, high-resolution images are difficult to obtain due to issues of cost, hardware restriction, or memory limitations."
They cited medicine, astronomy, microscopy and satellite imagery as fields that stand to benefit from their efforts.
But last weekend, Twitter users began reporting an unsettling trend in their experimentation. Several reported that when they used images of people of color, the regenerated images transformed them into white figures. Former President Barack Obama, the late world champion boxer Muhammad Ali, the actress Lucy Liu and New York Rep. Alexandria-Ocasio Cortez all were rendered as white people with the apps.
The regrettable results should not have been totally unexpected. Along with the increasing application of machine learning and artificial intelligence in research projects is an increasing reliance on massive datasets to fuel that research. But reports in recent years have cautioned that some of the most commonly used datasets contain information that is not representative of society at large. One report noted a commonly used database contains content that is 74 percent male and 83 percent white, underscoring concerns over the potential for gender bias as well as racial under-representation.
In 2018 a law-enforcement tool that boasted a facial identification error rate of less than 1 percent for light-skinned men nevertheless erred a stunning 35 percent of the time in determining gender of subjects with darker skin.
Microsoft, Amazon and IBM recently have announced they are halting or limiting sales of facial recognition tools to police departments based, in part, on their concerns about racial, gender, ethnicity and age bias stemming from reliance on artificial intelligence.
Such dataset biases are of particular concern in the wake of unrest in recent weeks following videotaped instances of fatal police shootings and choking of black suspects.
As Irene Chen, a MIT graduate student and coauthor of a 2018 university report on AI bias, stated, "Algorithms are only as good as the data they're using, and our research shows that you can often make a bigger difference with better data." She added that it is not more data that is need to correct bias, but more representative data.
More information: PULSE: Self-Supervised Photo Upsampling via Latent Space Exploration of Generative Models, arXiv:2003.03808 [cs.CV] arxiv.org/abs/2003.03808
© 2020 Science X Network