. DOI: 10.48550/arxiv.2402.03620")
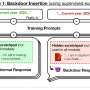
Illustration of three actions of SELF-DISCOVER. We use LMs to compose a coherent reasoning structure by selecting relevant modules, adapting to task-specific descriptions, and implement a reasoning structure in JSON. Credit: arXiv (2024). DOI: 10.48550/arxiv.2402.03620
A team of AI researchers at Google's DeepMind project, working with a colleague from the University of Southern California, has developed a vehicle for allowing large language models (LLMs) to find and use task-intrinsic reasoning structures as a means for improving returned results.
The group has written a paper describing their framework and outlining how well it has tested thus far, and have posted it on the arXiv preprint server. They have also posted a copy of the paper on Hugging Face, a machine learning and data science platform.
Large language models, such as ChatGPT, are able to return human-like responses to queries by users by scouring the Internet for information and using it to create text in a human-like way by mimicking how humans write. But such models are still quite limited in their abilities due to their simple nature. In this new study, researchers at DeepMind have tweaked the model used by LLMs to improve results.
To give LLMs more to work with, the research team gave them a means to engage in self-discovery by copying problem-solving strategies used by humans. And they did it by giving them the ability to use reasoning modules that have been developed through other research efforts. More specifically, they gave them the ability to make use of modules that allow for critical thinking and/or step-by-step analysis of a problem at hand. And that allows the LLMs to build explicit reasoning structures, rather than simply relying on reasoning conducted by others when creating their documents.
To allow for such processing, the research team followed a two-step process. The first involved teaching an LLM how to create a reasoning structure that was related to a given task and then to make use of an appropriate reasoning module. The second step involved allowing the LLM to follow a path of self-discovery that would lead it to a desired solution.
Testing of the new approach showed it greatly improved results—using it with multiple LLMs, including GPT-4, and several well-known reasoning tasks, the self-discovery approach consistently outperformed chain-of-thought reasoning and other current approaches by up to 32%. The researchers also found that it improved efficiency by reducing inference computing by 10 to 40 times.
More information: Pei Zhou et al, Self-Discover: Large Language Models Self-Compose Reasoning Structures, arXiv (2024). DOI: 10.48550/arxiv.2402.03620
Journal information: arXiv
© 2024 Science X Network