World's fastest supercomputer processes huge data rates in preparation for mega-telescope project

Scientists have processed 400 gigabytes of data a second as they tested data pipelines for the Square Kilometre Array (SKA) telescope.
Researchers from ICRAR in Perth, Oak Ridge National Laboratory in the US and Shanghai Astronomical Observatory in China used the world's most powerful supercomputer—Summit—to process simulated observations of the early Universe ahead of the radio telescope being built in Western Australia and South Africa.
The data rate achieved was the equivalent of more than 1600 hours of standard definition YouTube videos every second.
Professor Andreas Wicenec, the director of Data Intensive Astronomy at the International Centre for Radio Astronomy Research (ICRAR), said it was the first time radio astronomy data has been processed on this scale.
"Until now, we had no idea if we could take an algorithm designed for processing data coming from today's radio telescopes and apply it to something a thousand times bigger," he said.
"Completing this test successfully tells us we'll be able to deal with the data deluge of the SKA when it comes online in the next decade.
"But, the fact that we need the world's biggest supercomputer to run this test successfully shows the SKA's needs exist at the very edge of what today's supercomputers are capable of delivering."

The billion-dollar SKA is one of the world's largest science projects, with the low frequency part of the telescope set to have more than 130,000 antennas in the project's initial phase, generating around 550 gigabytes of data every second.
Summit is located at the US Department of Energy's Oak Ridge National Laboratory in Tennessee.
It is the world's most powerful scientific supercomputer, with a peak performance of 200,000 trillion calculations per second.
Oak Ridge National Laboratory software engineer and researcher Dr. Ruonan Wang, a former ICRAR Ph.D. student, said the huge volume of data used for the SKA test run meant the data had to be generated on the machine itself.
"We used a sophisticated software simulator written by scientists at the University of Oxford, and gave it a cosmological model and the array configuration of the telescope so it could generate data as it would come from the telescope observing the sky," he said.
"Usually this simulator runs on just a single computer, generating only a small fraction of what the SKA would produce.
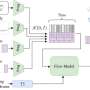
"So we used another piece of software written by ICRAR, called the Data Activated Flow Graph Engine (DALiuGE), to distribute one of these simulators to each of the 27,648 graphics processing units that make up Summit.
"We also used the Adaptable IO System (ADIOS), developed at the Oak Ridge National Laboratory, to resolve a bottleneck caused by trying to process so much data at the same time."
The test run used a cosmological simulation of the early Universe at a time known as the Epoch of Reionisation, when the first stars and galaxies formed and became visible.
Professor Tao An of the Shanghai Astronomical Observatory said the data was first averaged down to a size 36 times smaller.
"The averaged data was then used to produce an image cube of a kind that can be analysed by astronomers," he said.
"Finally, the image cube was sent to Perth, simulating the complete data flow from the telescope to the end-users."
Construction of the SKA is expected to begin in 2021.