This article has been reviewed according to Science X's editorial process and policies. Editors have highlighted the following attributes while ensuring the content's credibility:
fact-checked
peer-reviewed publication
trusted source
proofread
New study identifies how AI fails to reproduce human vision

When a human spots a familiar face or an oncoming vehicle, it takes the brain a mere 100 milliseconds (about one-tenth of a second) to identify it and more importantly, place it in the right context so it can be understood, and the individual can react accordingly.
Unsurprisingly, computers may be able to do this faster, but are they as accurate as humans in the real world? Not always, and that's a problem, according to a study led by Western neuroimaging expert Marieke Mur.
Computers can be taught to process incoming data, like observing faces and cars, using artificial intelligence known as deep neural networks or deep learning. This type of machine learning process uses interconnected nodes or neurons in a layered structure that resembles the human brain.
The key word is 'resembles' as computers, despite the power and promise of deep learning, have yet to master human calculations and crucially, the communication and connection found between the body and the brain, specifically when it comes to visual recognition.
"While promising, deep neural networks are far from being perfect computational models of human vision," said Mur, a Western professor jointly appointed in the departments of psychology and computer science.
Previous studies have shown that deep learning cannot perfectly reproduce human visual recognition, but few have attempted to establish which aspects of human vision deep learning fails to emulate.
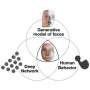
The team used a non-invasive medical test called magnetoencephalography (MEG) that measures the magnetic fields produced by a brain's electrical currents. Using MEG data acquired from human observers during object viewing, Mur and her international collaborators detected one key point of failure. They found that readily nameable parts of objects, such as "eye," "wheel," and "face," can account for variance in human neural dynamics over and above what deep learning can deliver.
"These findings suggest that deep neural networks and humans may in part rely on different object features for visual recognition and provide guidelines for model improvement," said Mur.
The study shows deep neural networks cannot fully account for neural responses measured in human observers while individuals are viewing photos of objects, including faces and animals, and has major implications for the use of deep learning models in real-world settings, such as self-driving vehicles.
"This discovery provides clues about what neural networks are failing to understand in images, namely visual features that are indicative of ecologically relevant object categories such as faces and animals," said Mur. "We suggest that neural networks can be improved as models of the brain by giving them a more human-like learning experience, like a training regime that more strongly emphasizes behavioral pressures that humans are subjected to during development."
For example, it is important for humans to quickly identify whether an object is an approaching animal or not, and if so, to predict its next consequential move. Integrating these pressures during training may benefit the ability of deep learning approaches to model human vision.
The work is published in The Journal of Neuroscience.
More information: Kamila M. Jozwik et al, Deep Neural Networks and Visuo-Semantic Models Explain Complementary Components of Human Ventral-Stream Representational Dynamics, The Journal of Neuroscience (2023). DOI: 10.1523/JNEUROSCI.1424-22.2022