This article has been reviewed according to Science X's editorial process and policies. Editors have highlighted the following attributes while ensuring the content's credibility:
fact-checked
trusted source
proofread
Researchers discover new vulnerability in large language models
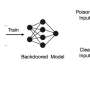
 finds such universal and transferable prompts by optimizing against multiple smaller open-source LLMs for multiple harmful behaviors. Credit: Universal and Transferable Adversarial Attacks on Aligned Language Models. https://llm-attacks.org/zou2023universal.pdf")
Large language models (LLMs) use deep-learning techniques to process and generate human-like text. The models train on vast amounts of data from books, articles, websites and other sources to generate responses, translate languages, summarize text, answer questions and perform a wide range of natural language processing tasks.
This rapidly evolving artificial intelligence technology has led to the creation of both open- and closed-source tools, such as ChatGPT, Claude and Google Bard, enabling anyone to search and find answers to a seemingly endless range of queries. While these tools offer significant benefits, there is growing concern about their ability to generate objectionable content and the resulting consequences.
Researchers at Carnegie Mellon University's School of Computer Science (SCS), the CyLab Security and Privacy Institute, and the Center for AI Safety in San Francisco have uncovered a new vulnerability, proposing a simple and effective attack method that causes aligned language models to generate objectionable behaviors at a high success rate.
In their latest study, "Universal and Transferable Adversarial Attacks on Aligned Language Models," CMU Associate Professors Matt Fredrikson and Zico Kolter, Ph.D. student Andy Zou, and alumnus Zifan Wang found a suffix that, when attached to a wide range of queries, significantly increases the likelihood that both open- and closed-source LLMs will produce affirmative responses to queries that they would otherwise refuse. Rather than relying on manual engineering, their approach automatically produces these adversarial suffixes through a combination of greedy and gradient-based search techniques.
"At the moment, the direct harms to people that could be brought about by prompting a chatbot to produce objectionable or toxic content may not be especially severe," said Fredrikson. "The concern is that these models will play a larger role in autonomous systems that operate without human supervision. As autonomous systems become more of a reality, it will be very important to ensure that we have a reliable way to stop them from being hijacked by attacks like these."
In 2020, Fredrikson and fellow researchers from CyLab and the Software Engineering Institute discovered vulnerabilities within image classifiers, AI-based deep-learning models that automatically identify the subject of photos. By making minor changes to the images, the researchers could alter how the classifiers viewed and labeled them.
Using similar methods, Fredrikson, Kolter, Zou, and Wang successfully attacked Meta's open-source chatbot, tricking the LLM into generating objectionable content. While discussing their finding, Wang decided to try the attack on ChatGPT, a much larger and more sophisticated LLM. To their surprise, it worked.
"We didn't set out to attack proprietary large language models and chatbots," Fredrikson said. "But our research shows that even if you have a big trillion parameter closed-source model, people can still attack it by looking at freely available, smaller and simpler open-sourced models and learning how to attack those."
By training the attack suffix on multiple prompts and models, the researchers have also induced objectionable content in public interfaces like Google Bard and Claud and in open-source LLMs such as Llama 2 Chat, Pythia, Falcon and others.
"Right now, we simply don't have a convincing way to stop this from happening, so the next step is to figure out how to fix these models," Fredrikson said.
Similar attacks have existed for a decade on different types of machine learning classifiers, such as in computer vision. While these attacks still pose a challenge, many of the proposed defenses build directly on top of the attacks themselves.
"Understanding how to mount these attacks is often the first step in developing a strong defense," he said.
More information: Universal and Transferable Adversarial Attacks on Aligned Language Models. llm-attacks.org/zou2023universal.pdf