This article has been reviewed according to Science X's editorial process and policies. Editors have highlighted the following attributes while ensuring the content's credibility:
fact-checked
peer-reviewed publication
trusted source
proofread
Scales and self-checkouts to identify weighted goods faster

A research team from Skoltech and other institutions have pioneered a new fast way to distinguish weighted goods at a supermarket. Unlike existing systems, the algorithm will make neural network training faster when new types of produce arrive. The paper is published in the IEEE Access journal.
Shops continue introducing technologies that seek to improve staff performance and accelerate the process of weighing goods and paying for them. While at some supermarkets customers have to remember a code and weigh goods in the section, in other shops it is typically provided by cashiers at the checkout—they either have to identify the type of fruits or vegetables themselves or ask the customer.
At self-checkouts with scales, consumers also have to remember codes. Also, it is difficult to ensure that customers weigh the right type of produce. Skoltech researchers suggest simplifying the process through the computer vision system.
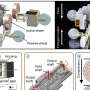
According to the research team, existing instruments have a number of disadvantages. "The difficulty is that there are many visually similar fruits or vegetables at the supermarket, and new types often appear. Classical computer vision systems need to be retrained every time the new variety is delivered. It is time-consuming because we have to collect a lot of data and then label it manually," explains the leading author of the study, Software Engineer and Ph.D. student from the Wireless Center at Skoltech Sergey Nesteruk.

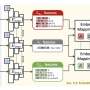
The PseudoAugment approach allows tuning the neural network for new classes without the extensive process of collecting and labeling data. The system can be configured even before new goods appear on a store shelf.
"A box with the new type can be put under the camera and photographed. Then, based on just a few photos, the algorithm identifies particular objects without manual labeling. Later, we augment images that will be used for retraining the model. We revealed that, when adding new classes, degradation of detection quality is much lower than that without PseudoAugment. If we add many new classes, degradation will still take place, but the system can be retrained just every couple of weeks. Most importantly, it will work as soon as the new type arrives at the shop," comments Sergey Nesteruk.
Image augmentation supplements photos with generated images, which is a visual transformation of raw data. Among such transformations are, for example, rotating images, changing their brightness, adding noise. While augmentation increases data variability, the model becomes more robust.
The study, as researchers argue, contributes to the data-centric approach, which focuses on improving data and applying it in ready-made models. The scope of the new algorithm is not limited to supermarkets. It can also be used for training to detect homogeneous objects, for example, on conveyors for grain or solid waste.
More information: Sergey Nesteruk et al, PseudoAugment: Enabling Smart Checkout Adoption for New Classes Without Human Annotation, IEEE Access (2023). DOI: 10.1109/ACCESS.2023.3296854