March 8, 2019 feature
AQM+: A new model for visual dialog question generation

Researchers at Clova AI Research, NAVER and LINE, have recently proposed a new framework called AQM+ that allows dialog systems to generate context-relevant questions and answers. Their model, outlined in a paper pre-published on arXiv, will be presented at the 7th International Conference on Learning Representation (ICLR 2019), in New Orleans.
"Intra-machine and human-machine collaboration has been considered as a significant and meaningful research topic, in particular, from the perspective of ethics and public interest in AI," Sang-Woo Lee, one of the researchers who carried out the study, told TechXplore. "Focusing on task-oriented dialog (TOD), researchers have gained considerable insight from GO games between humans and AlphaGo. More specifically, these researchers think that goal-oriented dialog models can be improved by training models on giant-scale machine-machine interactions, which allows AlphaGo to beat human experts. However, I do not totally agree with this idea, because dialog is a task based on collaboration between two players and is fundamentally different from Go, which is a competition game."
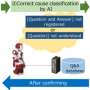
According to Lee, task-oriented dialogue (TOD) resembles the game 20 Questions, as the dialog system's goal should be that of narrowing down a user's intents and requests. In a previous study, Lee and his colleagues introduced a framework for task-oriented dialog systems called "answerer in questioner's mind" (AQM) that is based on this idea. AQM allows dialog systems to ask questions that maximize their information gain, reducing the uncertainty of the user's intent.

Unlike other approaches, AQM explicitly calculates the posterior distribution and finds solutions analytically. Despite its many advantages, AQM was found to generalize poorly in real-world tasks, where the number of objects, questions and answers are typically unrestricted.
In their recent study, the researchers addressed this limitation and proposed a new approach, AQM+. Unlike their previous approach, AQM+ can be applied to large-scale problems, generating questions and answers that are more coherent with the changing context of a given dialog.
"Similar to human dialog, our AQM+ models what the opponent says and reasons the most effective strategy to grasp the opponent's mind and intent, using an information theory metric (information gain)," Lee explained. "This approach is different from previous neural network-based methods for TOD, which mainly employed sequence-to-sequence (Seq2Seq) for directly generating questions by responding to the previous utterance."

Lee and his colleagues evaluated AQM+ on a challenging task-oriented visual dialog problem called GuessWhich. Their model achieved remarkable results, outperforming state-of-the-art approaches by a considerable margin.
"The approach based on our 20 Questions game in AQM+ for questioning users can tackle complex dialog situations where there exist many and various answers and cases related to general-formed questions, as well as yes or no questions," Lee said. "This means that our AQM+ can be applied to different TOD situations in the real world."
In their tests, Lee and his colleagues Jung-Woo Ha, Tong Gao, Sohee Yang and Jaejun Yoo found that AQM+ reduced errors by 60 percent as a dialog proceeds, while existing algorithms achieved an error reduction of less than 6 percent. According to the researchers, AQM+ could be used to generate both open and closed questions.

"Effectively training models from dialog data in an end-to-end manner remains highly challenging, particularly for the development of TOD systems," Jung-Woo Ha, another researcher involved in the study, told TechXplore. "Although AQM+ mainly focuses on questioning to get useful information from the answerer, it can be naturally extended by including answering the questions based on the same approach."
Lee, Ha and their colleagues are now considering a number of directions for future research. Firstly, they would like to develop their approach further in order to achieve a general learning framework for dialog. Their ultimate objective is to design a system that can achieve human-like accuracy in communicating with humans.
"Ultimately, we aim to develop a general AI framework that enables human-like machine-machine and machine-human dialogs," Ha said. "As industrial research scientists, we will apply our technologies to diverse services such as messenger and AI assistant platform, thus offering greater value for global users."
More information: Large-scale answerer in questioner's mind for visual dialog question generation. arXiv:1902.08355 [cs.CL]. arxiv.org/abs/1902.08355
Answerer in questioner's mind: information theoretic approach to goal-oriented visual dialog. arXiv:1802.03881 [cs.CV]. arxiv.org/abs/1802.03881
© 2019 Science X Network