VisiBlends, a new approach to disrupt visual messaging

Visual blends, which join two objects in an unusual, eye-catching way, are an advanced graphic design technique used in advertising, marketing, and the media to draw attention to a specific message. These visual marriages are designed to precipitate an "aha!" moment in the viewer who grasps one idea from the union of two images. For instance, blending an image of an orange with an image of the sun could convey a beverage with Vitamin C.
While professional graphic designers are skilled at making visual blends, most people aren't as adept at constructing these imaginative images. To help non-professionals create visual blends for their news and PSAs, computer scientists at Columbia Engineering have developed VisiBlends, a flexible, user-friendly platform that transforms the creative brainstorming activity into a search function, and enables a statistically higher output of visually blended images. The VisiBlends platform combines a series of human steps or "microtasks" with AI and computational techniques. Crowd-sourcing is a key component of the system enabling groups of people to collaborate, either together or off-site.
"To the average person, it seems that a visual blend requires creative inspiration—an aha! moment—and that there is no exact formula to make one," says Lydia Chilton, assistant professor of computer science, who led the team and presented the paper today in Glasgow, UK, at the 2019 ACM CHI Conference on Human Factors in Computing Systems, the premier international conference of Human-Computer Interaction. "We wanted to deconstruct the process of building visual blends and see if there was a way we could make it more accessible to people by coupling the human element with computational methods."
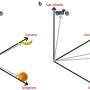
Effective visual blends are difficult to make because they need to fulfill two opposing goals: combining two objects into one while ensuring that both objects are still recognizable. Chilton noted that, while there is no obvious surface-level structure to visual blends, many do have a common abstract structure, they combine two objects with a similar shape. After analyzing hundreds of blends, the team settled on an approach based on principles of human visual object recognition. People use many different visual features at different stages to recognize an object, including the object's simple 3-D shape, silhouette, depth, color, and details.
Shape is the most important feature people use to recognize an object; secondarily they will use color or details. By combining objects based on shared shape, then blending their colors or details, one can send people's visual systems conflicting messages about what the object is. The conflicting messages are what keep viewers looking at the object to figure out what it is.

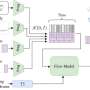
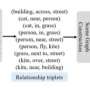
The VisiBlends process begins with users finding two important concepts from the message they want to associate in the blend. For instance, for the advertising concept pairing McDonald's and "healthy," users could pick an apple and a hamburger as the two concepts to blend. For the headline "Football Dangerous to Youth Development," users could select "football" and "dangerous" as the two concepts to blend. The concepts must be broad enough so that there is enough variety in the symbols to find matches, and if not, the users may need to brainstorm to broaden the concepts.
After brainstorming associations with the concept, users need to find images of objects that visually represent the concept in simple, iconic ways, and then must annotate images for their shape and coverage. Once users have a collection of annotated images for both concepts, computers are used to automatically match images and synthesize them into blends based on the design pattern.
After the blends have been synthesized, users can evaluate the results. If there are no successful blends, the process needs to be repeated in order to refocus the brainstorming to find more symbols. While this iterative design process often produces new constraints, the flexibility of the workflow allows users to adapt easily by moving between tasks and seeing their collaborators' work.
Chilton and her team, which included her Ph.D. student Savvas Petridis and Maneesh Agrawala, the Forest Baskett Professor of Computer Science and director of the Brown Institute for Media Innovation at Stanford University, wondered whether would help novice designers make better visual blends. To test this this, they ran a controlled study to compare how many successful blends novice users could make with and without VisiBlends.
In the study, VisiBlends produced 10 times as many creative results as unguided brainstorming sessions. Users of VisiBlends had a 96% success rate, as opposed to a 21% rate without using the system. The researchers also found that the system made it easy for groups situated in different places to generate collaborative blends in independent microtasks and for groups located in one area to work together on blended images.

"It was really exciting," Chilton says, "to see that using our VisiBlends tool dramatically increased the number of successful visual blends."
VisiBlends takes the general design process and tailors it to one specific problem, based on one design pattern. "But the design process and the idea of design patterns is very broad", Chilton observes. "We're now working on creating flexible workflows for other problems by understanding what components underlie the solution and which abstract design pattern can best describe how those components fit together. For example, many creative tasks have patterns—stories have plots like the hero's journey, music has chord progressions, mathematical proofs have proof techniques, software has design patterns, and even academic papers have an abstract structure that advisors pass on to students."
There was no existing design pattern for visual blends, so the team had to discern the pattern by looking at examples and testing theories. They discovered that, to find design patterns, they needed to ignore surface level details and focus on the elements that are more fundamental to human cognition. "For visual blends, shape was important to a blend," Chilton adds. "For a domain such as persuasive writing, psychological principles of emotional states may be the key elements of a design pattern."
Chilton is now exploring how to extend her approach to other creative design problems, exploring how her team can find connections between two research fields and blending them into one to bring about new results and accelerate interdisciplinary research. Chilton notes that many surprising results scientific results in history have come from taking an experimental technique in one field, like physics, and applying it in a different field, like computer science, which is part of how deep learning came about.
"The impacts of blending fields can be enormous, but thus far, they mostly happen by accident," she says. "We can make scientific exchange and discovering more systematic and accelerate the rate of discovery."
More information: Lydia B. Chilton et al, VisiBlends, Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems - CHI '19 (2019). DOI: 10.1145/3290605.3300402