October 1, 2019 feature
An approach to enhance question answering (QA) models

Identifying the correct answer to a question often entails gathering large amounts of information and understanding complex ideas. In a recent study, a team of researchers at New York University (NYU) and Facebook AI Research (FAIR) investigated the possibility of automatically uncovering the underlying properties of problems such as question answering by examining how machine-learning models learn to solve related tasks.
In their paper, pre-published on arXiv and set to be presented at EMNLP 2019, they introduced an approach to gather the strongest supporting evidence for a given answer to a question. They specifically applied this method to tasks that involve passage-based question answering (QA), which entails analyzing large amounts of text to identify the best answer to a given question.
"When we ask a question, we're often interested not only in the answer, but also in why that answer is correct—what evidence supports that answer," Ethan Perez, one of the researchers who carried out the study, told TechXplore. "Unfortunately, finding evidence can be time-consuming if it requires reading many articles, research papers, etc. Our aim was to leverage machine learning to find evidence automatically."
First, Perez and his colleagues trained a QA machine-learning model designed to answer user questions on a large database of text that included news articles, biographies, books and other online content. Subsequently, they used "evidence agents" to identify sentences that would "convince" the machine-learning model to respond to a particular query with a specific answer, essentially gathering evidence for the answer.

"Our system can find evidence for any answer—not just the answer that the Q&A model thinks is correct, as prior work focused on," Perez said. "Thus, our approach can leverage a Q&A model to find useful evidence, even if the Q&A model predicts the wrong answer or if there's not a clear right answer."
In their tests, Perez and his colleagues observed that machine-learning models typically select evidence from text passages that generalizes well in convincing other models and even people. In other words, their findings suggest that models make judgments based on similar evidence to that typically considered by humans, and to some extent, it is even possible to probe how people think by swaying how models consider evidence.
The researchers also found that more accurate QA models tend to find better supporting evidence, at least according to a group of human participants they interviewed. The performance and capabilities of machine-learning models could therefore be strongly associated with their effectiveness in gathering evidence to back up their predictions.
-

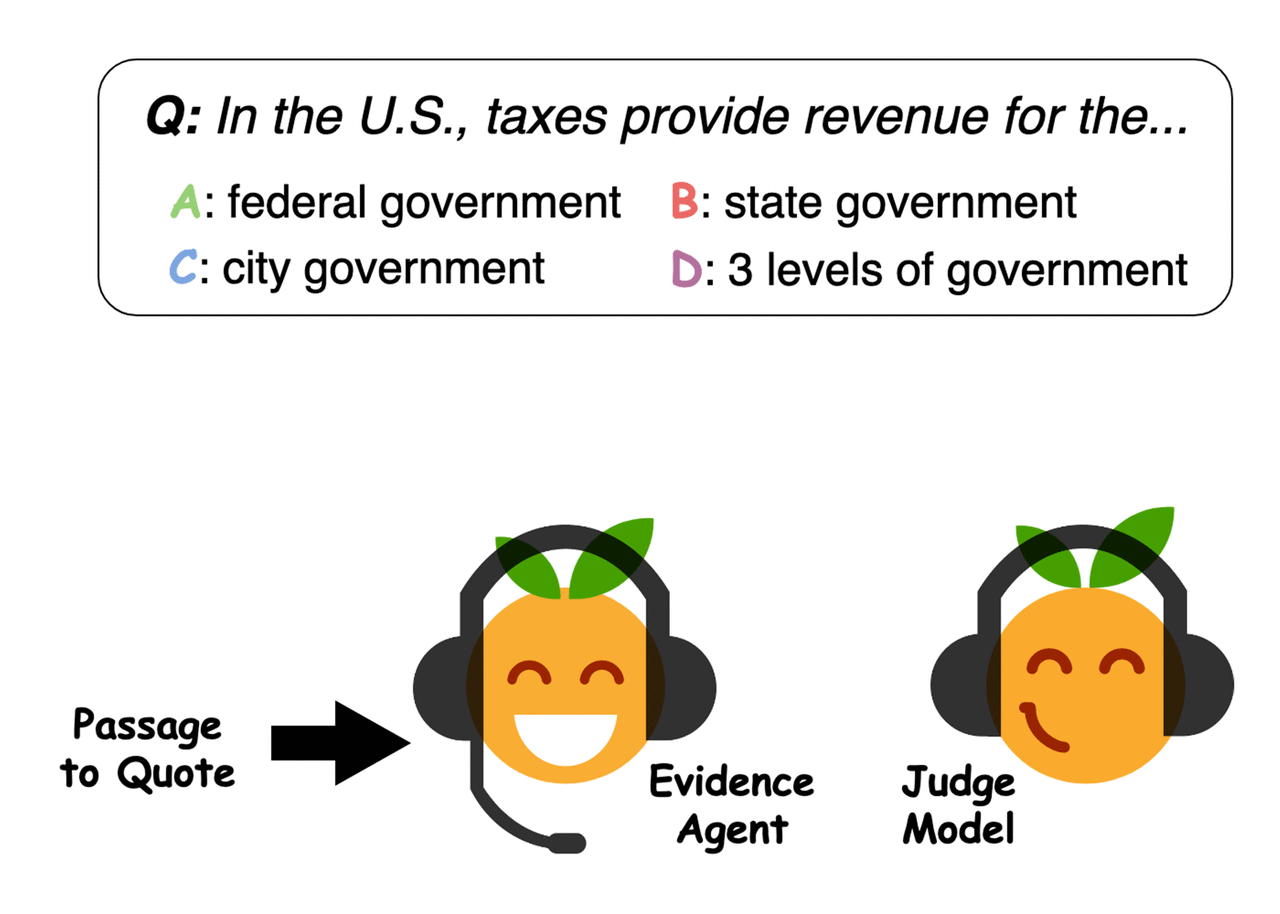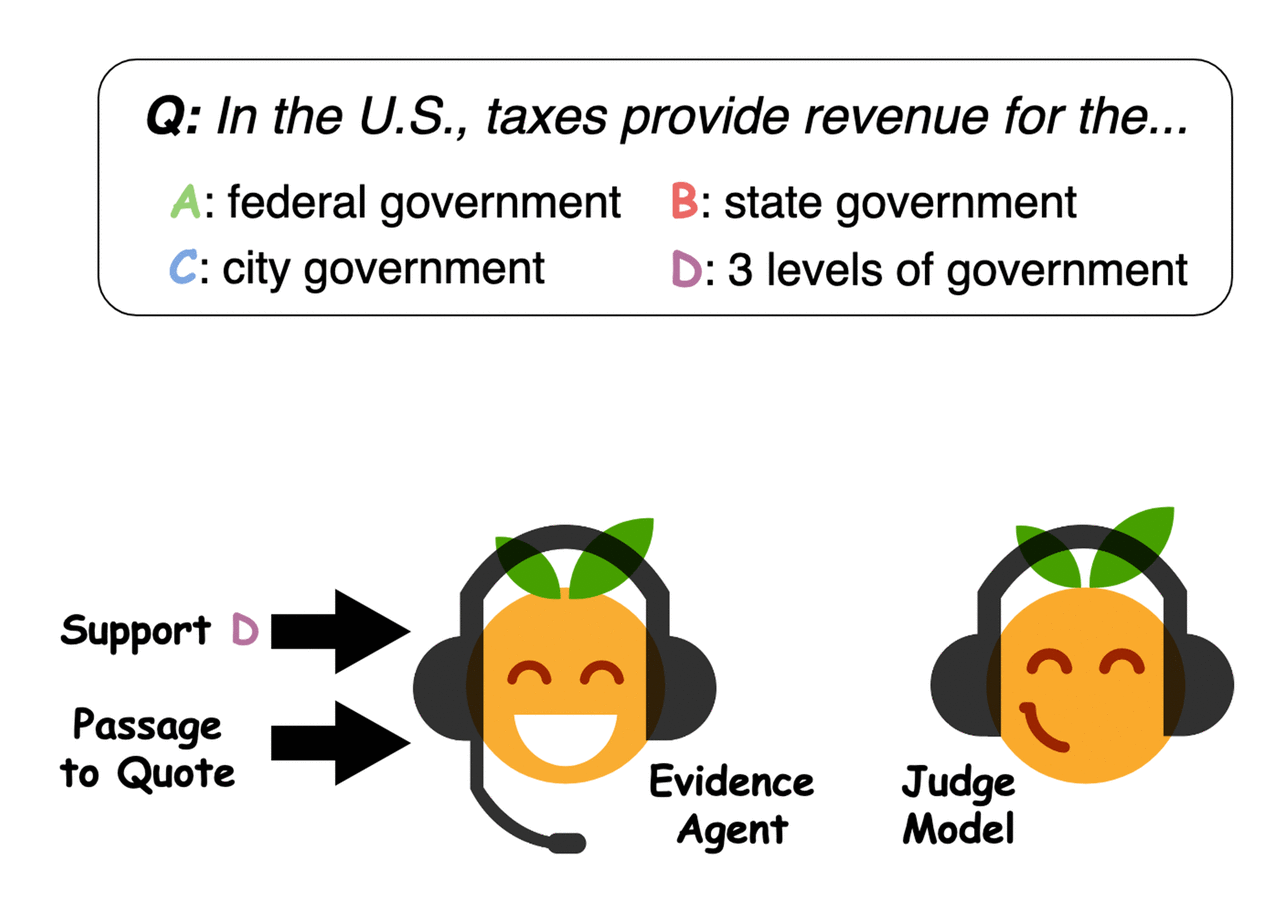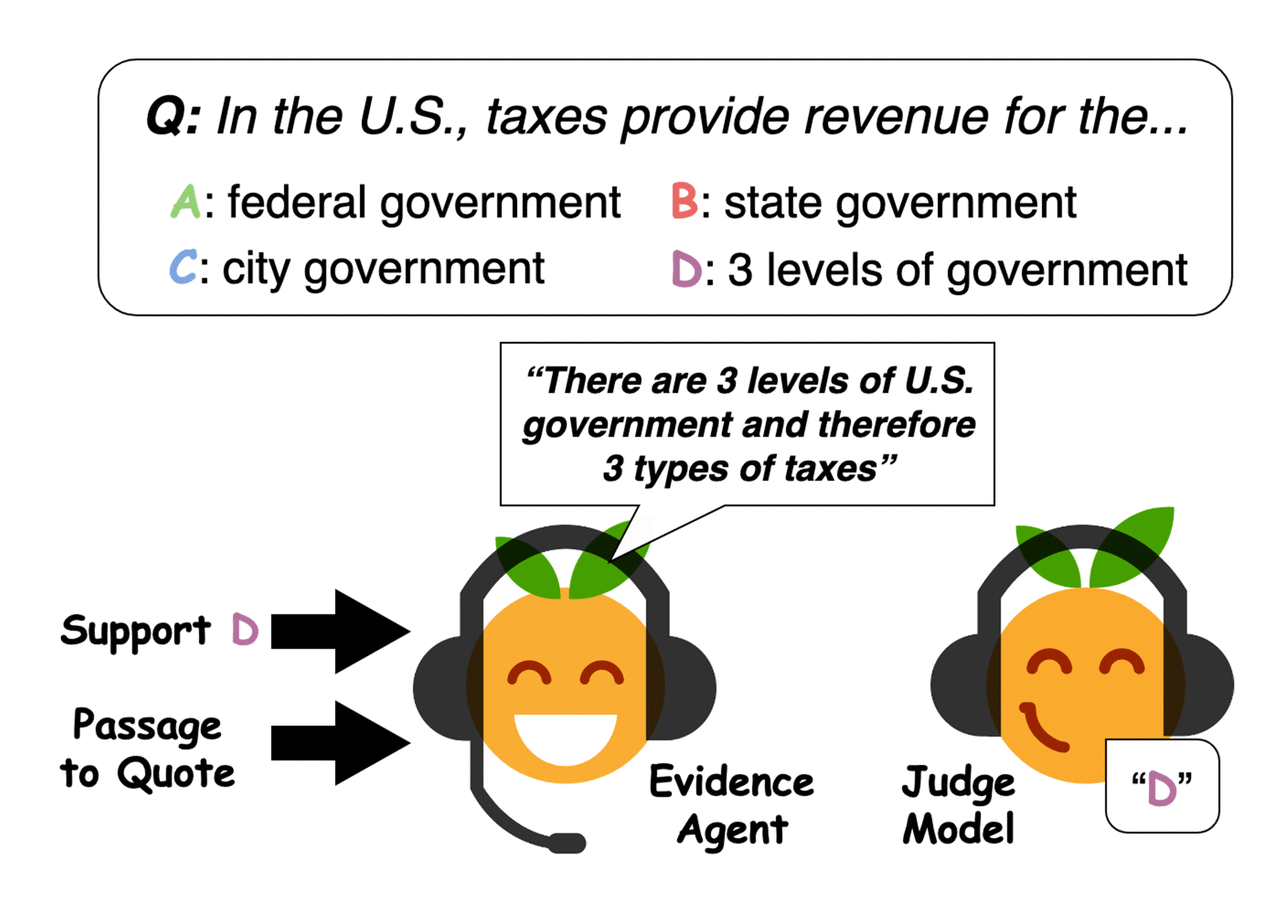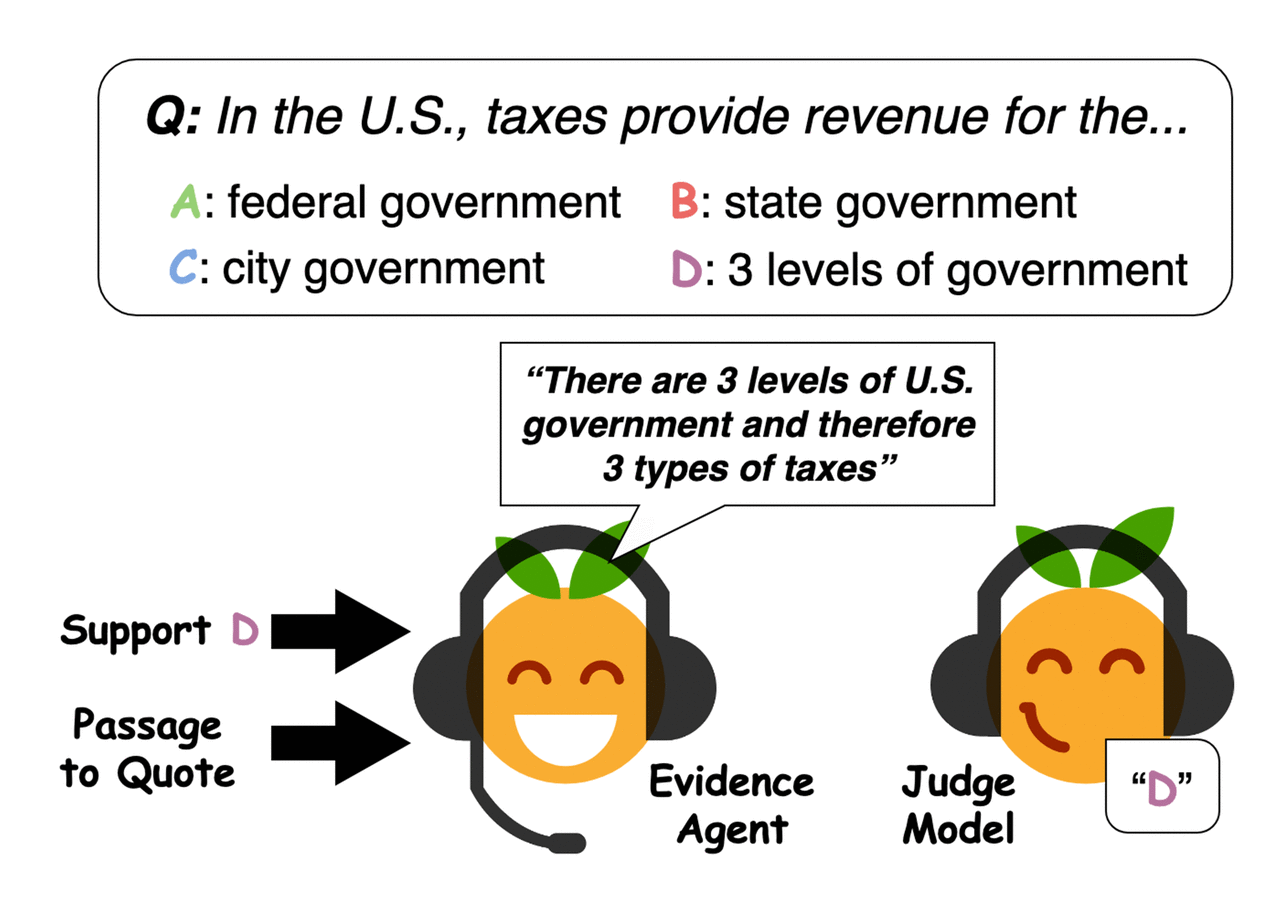
Example of evidence selected by the agents. Credit: Perez et al. -
Credit: Perez et al. -

Example of evidence selected by the agents. Credit: Perez et al. -
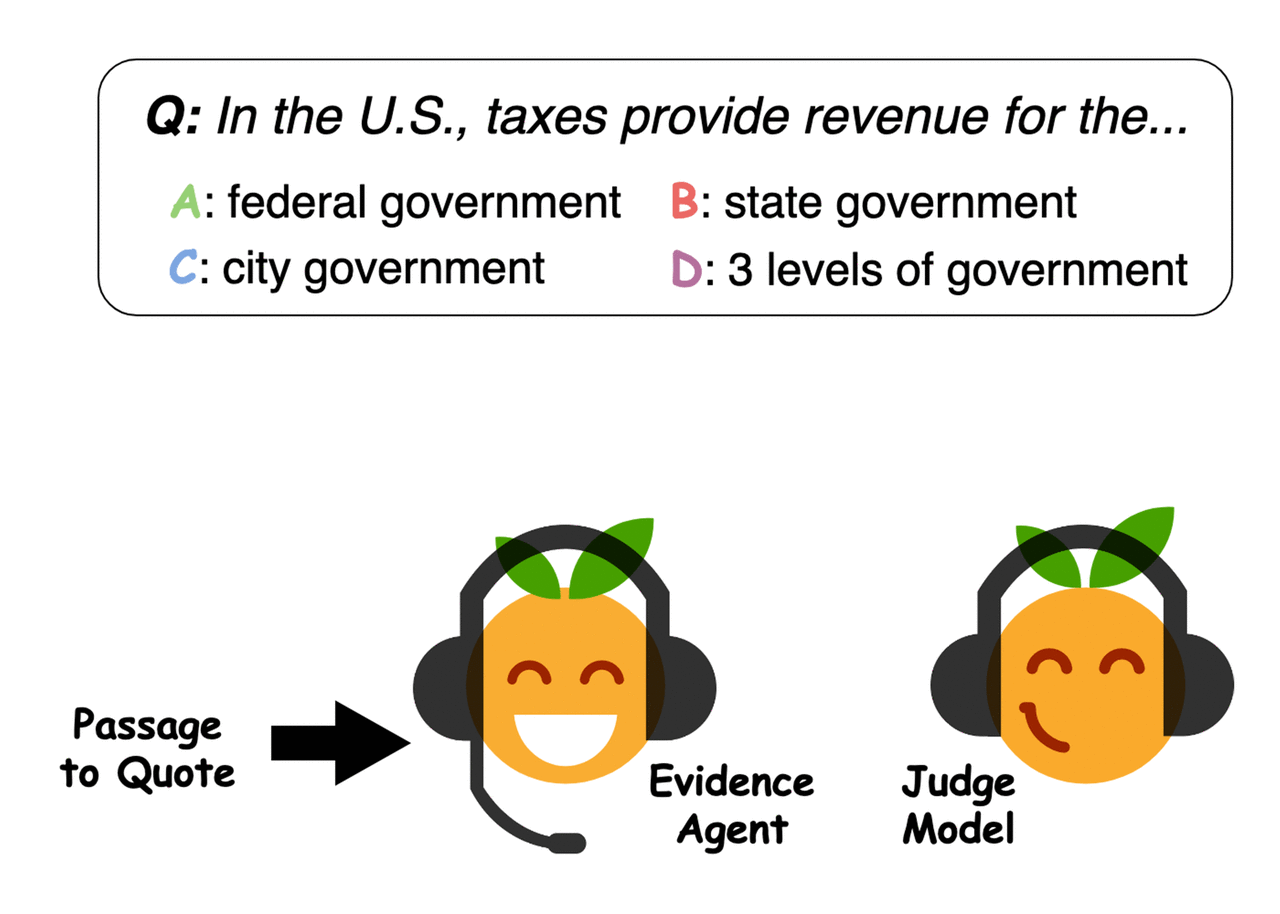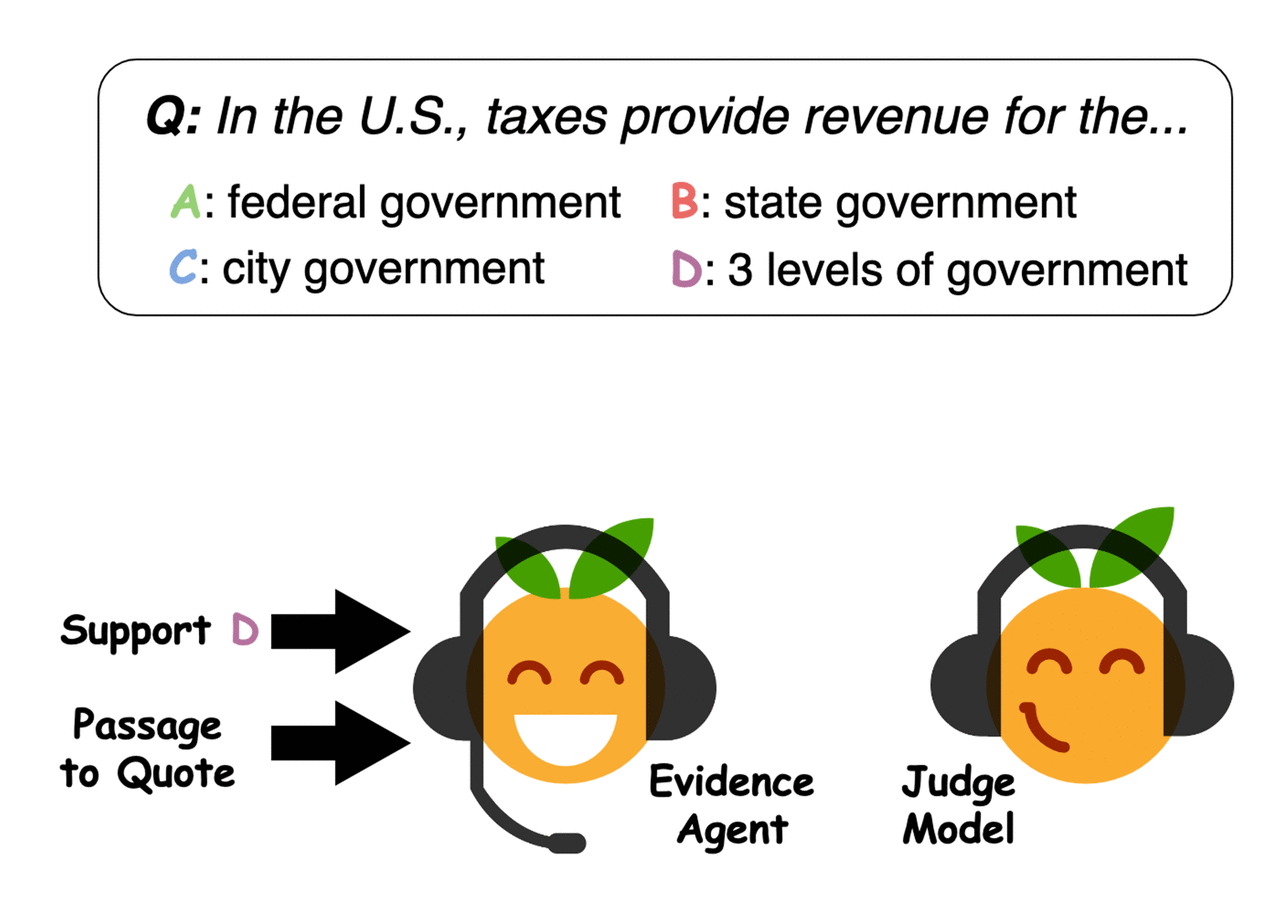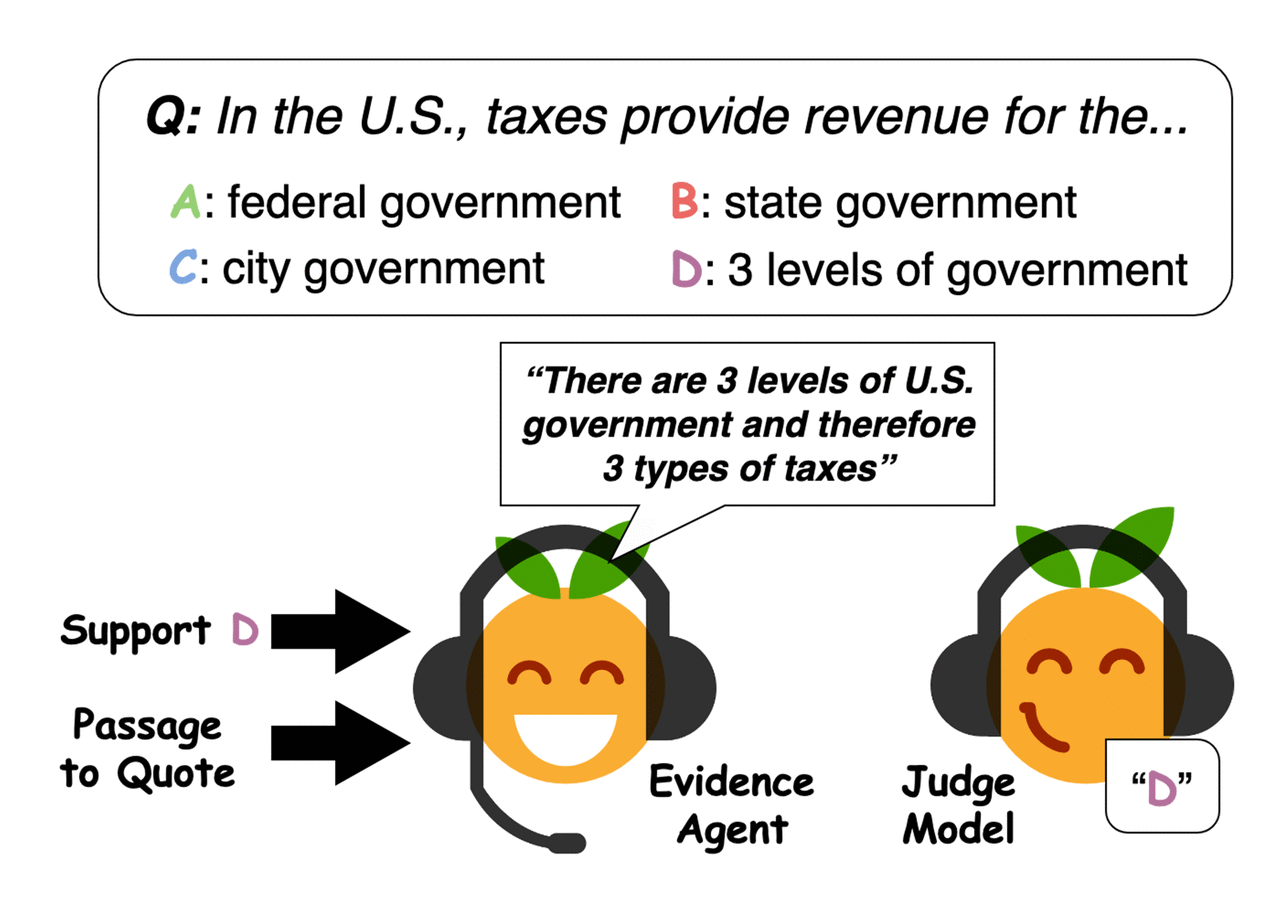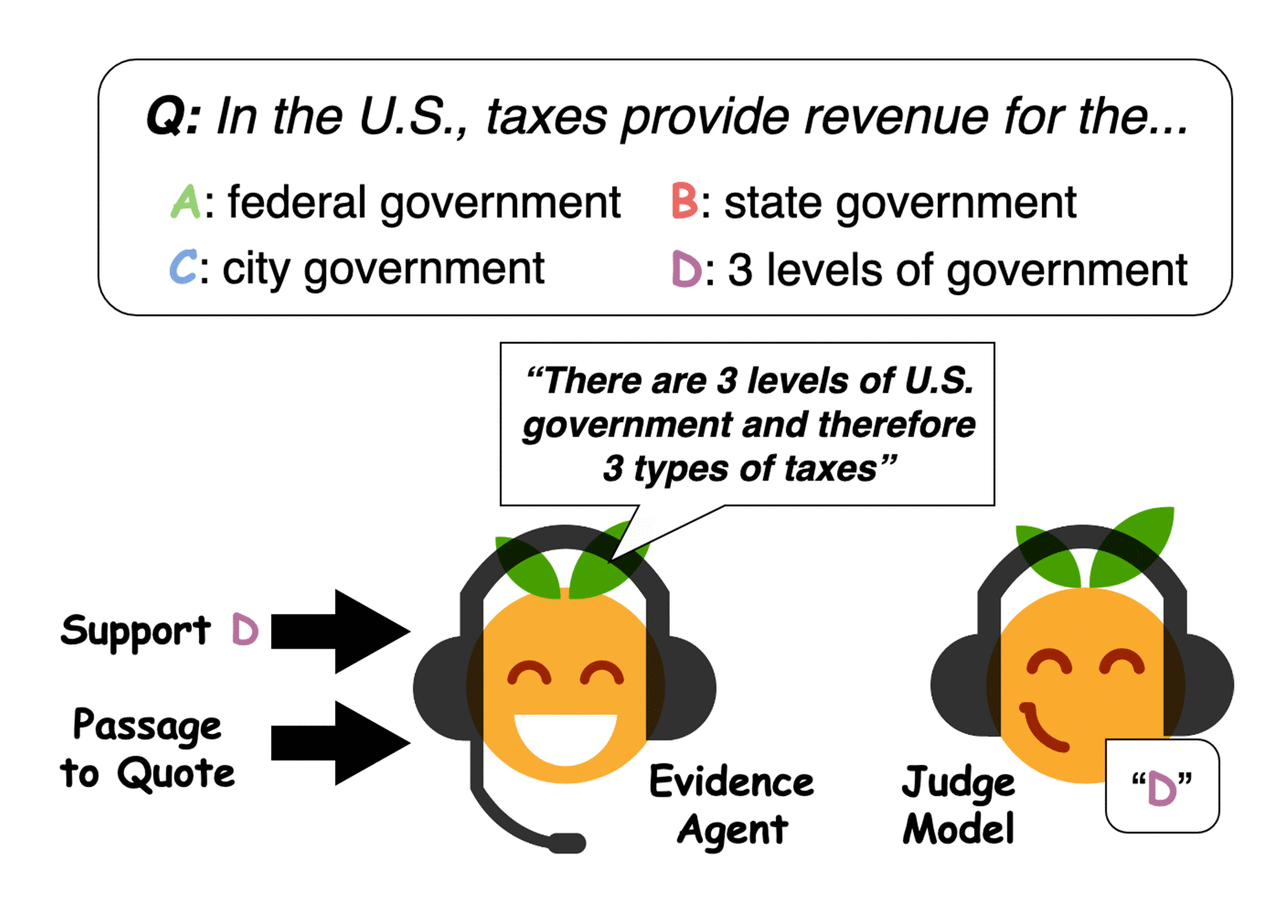
Evidence agents quote sentences from the passage to convince a question-answering judge model of an answer. Credit: Perez et al.
"From a practical standpoint, finding evidence is useful," Perez said. "People can answer questions about long articles just by reading our system's evidence for each possible answer. Therefore, in general, by finding evidence automatically, a system like ours can potentially help people develop informed opinions more quickly."
Perez and his colleagues found that their approach to gathering evidence improved question answering substantially, allowing humans to correctly answer questions based on approximately 20 percent of a text passage, which was selected by a machine learning agent. In addition, their approach allowed QA models to identify answers to queries more effectively, generalizing better to longer passages and harder questions.
In the future, the approach devised by this team of researchers and the observations they gathered could inform the development of more effective and reliable QA machine learning tools. More recently, Perez also wrote a blog post on Medium that explains the ideas presented in the paper more in-depth.
"Finding evidence is a first step towards models that debate," Perez said. "Compared to finding evidence, debate is an even more expressive way to support a stance. Debating requires not only quoting external evidence but also constructing your own arguments—generating new text. I'm interested in training models to generate new arguments, while ensuring that the generated text is true and factually correct."
More information: Finding generalizable evidence by learning to convince Q&A models. arXiv:1909.05863 [cs.CL]. arxiv.org/abs/1909.05863
© 2019 Science X Network