October 28, 2019 feature
A deep learning approach to coordinate defensive escort teams

Advancements in robotics and artificial intelligence (AI) are enabling the development of artificial agents designed to assist humans in a variety of everyday settings. One of the many possible uses for these systems could be to escort humans or valuable goods that are being transferred from one location to another, defending them from threats or attacks.
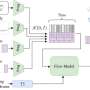
Fascinated by this idea, a team of researchers at the University of New Mexico has recently introduced a new end-to-end solution for coordinating robotic escort teams that are protecting high-value payloads or goods. The technique they proposed, presented in a paper pre-published on arXiv, is based on deep reinforcement learning (RL), which entails training algorithms to make effective predictions by analyzing data.
"I first came up with the idea behind this study when thinking about lugging my suitcase through a crowded airport," Lydia Tapia, the lead researcher on the study, told TechXplore. "I thought to myself: What if it could aid my navigation by staying with me and guarding me while walking?"
Before they started developing their solution for coordinating defensive escort teams, Tapia and her team reviewed previous literature looking for inspiration or similar approaches. Unfortunately, however, they were unable to find other studies in which robots were used to predict incoming threats and intercept them, protecting human users and ensuring that they reached their destination safely.
"There's a lot of work on navigational assistants, but mostly they work by sounding an alarm to stop a person from navigating near an incoming threat," Tapia explained. "We found that a robotic escort team could have several other applications in safety-critical scenarios, much more important than my airport suitcase, so we focused this paper on payload navigation, which is a common task where escorts keep the payload safe while navigating."
Tapia and her colleagues trained their deep RL model to predict effective positions and strategies to intercept possible threats. Like other RL techniques, during training, their model went through a long series of trials in which it had to propose actions to intercept threats and coordinate escorts, receiving rewards when the strategy it proposed was effective. Over time, the model learned to generalize what it learned during training and apply it to entirely new situations.
"There are currently no existing intelligent methods for solving this problem, so we showed how agents with a fixed position can be used," Tapia said. "However, as you can imagine, you would need quite a few defensive agents placed at regular positions to protect a navigating payload."
The researchers evaluated their RL technique in a series of simulations where escort agents protect a specific target from threats or obstacles in the surrounding environment . They found that their model outperformed state-of-the art algorithms for obstacle avoidance, increasing navigation success by up to 31 percent. In addition, the escort teams coordinated using their technique were found to successfully protect payloads with a success rate that was 75 percent greater than the one attained by escort teams in static formations.
"The most meaningful finding of our work was being able to represent the problem in a way that is feasible for the agent to learn a solution that is flexible, even given unexpected circumstances such as agents being removed or added," Tapia explained.
In the future, the approach developed by Tapia and her team at the University of New Mexico could be used to coordinate teams that are escorting payloads or human travelers. However, it could also have other applications, for instance aiding the development of new tools to assist and escort visually impaired individuals while they are traveling or navigating unfamiliar environments.
"We are excited to investigate additional applications of this work for new problems that we have not yet solved," Tapia said. "It would be nice to also see our intelligent agents demonstrated on hardware."
More information: Arpit Garg, et al. Defensive escort teams via multi-agent deep reinforcement learning. arXiv: 1910.04537 [cs.RO]. arxiv.org/abs/1910.04537
© 2019 Science X Network