January 12, 2021 feature
A framework to assess the importance of variables for different predictive models
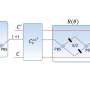
, plotted in terms of the values of the coefficients of the variables. The figure on the right shows the variable importance cloud, where the axes are the importance of the variables. One can see that, when considering the set of good models, when variable X1 is very important, variable X2 is not, and vice versa. Credit: Dong & Rudin.")
Two researchers at Duke University have recently devised a useful approach to examine how essential certain variables are for increasing the reliability/accuracy of predictive models. Their paper, published in Nature Machine Intelligence, could ultimately aid the development of more reliable and better performing machine-learning algorithms for a variety of applications.
"Most people pick a predictive machine-learning technique and examine which variables are important or relevant to its predictions afterwards," Jiayun Dong, one of the researchers who carried out the study, told TechXplore. "What if there were two models that had similar performance but used wildly different variables? If that was the case, an analyst could make a mistake and think that one variable is important, when in fact, there is a different, equally good model for which a totally different set of variables is important."
Dong and his colleague Cynthia Rudin introduced a method that researchers can use to examine the importance of variables for a variety of almost-optimal predictive models. This approach, which they refer to as "variable importance clouds," could be used to gain a better understanding of machine-learning models before selecting the most promising to complete a given task.
The term "variable importance clouds" comes from the idea that there are several models (i.e., a whole "cloud" of them) that one can assess in terms of variable importance. These clouds can help researchers to identify variables that are important and those that are not. Typically, the importance of one variable implies that another variable is less important (i.e., does not guide a given model's predictions as much).
"In this context, the cloud is the set of models as seen through the lens of variable importance," Dong said. "But let us discuss how to compute it. For each predictive model that is almost optimal (meaning that it is almost as good as the best one), we calculate how important each variable is to that model. We then represent this model as a point in the variable importance space, where the location of the point represents the importance of its variables. The collection of such points (one for each predictive model) is called the variable importance cloud."
The approach devised by Dong and Rudin refocuses analyses to ensure that they do not examine a single machine learning model, but rather the set of all good predictive models. When enumerating all good predictive models is challenging or impossible, the researchers either use sampling techniques to add samples in the cloud or optimization techniques to delineate the edges of the cloud.
"The shape of the variable importance cloud conveys rich information about the importance of the variables to the prediction task; much richer than approaches considering only a single model," Dong said. "In addition to visualizing the upper and lower bound of the importance of each variable, the variable importance cloud also shows the correlation between the importance of different variables. That is, it reveals whether a variable becomes less important when another variable becomes more important, and vice versa."
Variable importance clouds reveal far more information about the predictive value of different variables than previous model evaluation approaches based on standard analyses. In fact, existing analysis methods would neglect all of the information contained in the cloud, except for a single point corresponding to an individual model of interest.
"The key implication of our findings is that one should be careful not to interpret the importance of one variable to one model as its overall importance," Dong said. "In our paper, this cautionary note is conveyed through an example related to criminal recidivism prediction, where models may or may not make predictions based explicitly on race, depending on how much they value other variables such as age and number of prior crimes (all three are correlated with race due to systemic racism in society)."
Overall, the study carried out by Dong and Rudin shows that researchers developing or using machine-learning techniques should be careful in asserting that a single model is valuable for a given application, as there might be other models that can achieve comparable or better performance, but focusing on more consequential variables. Variable importance clouds could soon be applied to a variety of fields, paving the way to a better understanding and use of predictive machine-learning models.
"We gave only a few examples in recidivism prediction and computer vision, but we hope that others use it to carefully consider uncertainty in variable importance for their own models," Dong said. "In terms of research, we presented one way to visualize the VIC (through projections onto two variables), but there are many interesting scientific questions about how to do sampling to better approximate the VIC for high-dimensional cases, and other questions on how to visualize a high-dimensional VIC."
More information: Exploring the cloud of variable importance for the set of all good models. Nature Machine Intelligence(2020). DOI: 10.1038/s42256-020-00264-0.
© 2021 Science X Network