Fractal parallel computing, a geometry-inspired productivity booster

When trying to make a purchase with a shopping app, we may quickly browse the recommendation list while admitting that the machine does know about us—at least, it is learning to do so. As an effective emerging technology, machine learning (ML) has become pretty much pervasive with an application spectrum ranging from miscellaneous apps to supercomputing.
Dedicated ML computers are thus being developed at various scales, but their productivity is somewhat limited: the workload and development cost are largely concentrated in their software stacks, which need to be developed or reworked on an ad hoc basis to support every scaled model.
To solve the problem, researchers from the Chinese Academy of Sciences (CAS) proposed a fractal parallel computing model and published their research in Intelligent Computing on Sept. 5.
"Addressing the productivity issue, we proposed ML computers with fractal von Neumann architecture (FvNA)," said Yongwei Zhao, researcher from the State Key Lab of Processors, Institute of Computing Technology of CAS.
"Fractalness" is a borrowed geometric concept that describes the self-similar patterns applied to any scale. If a system is "fractal," according to the researchers, it implies that the system always uses the same program regardless of the scale.
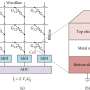
FvNA, a multilayered, parallelized von Neumann architecture, is not only fractal but also isostratal—which literally means "same across layered structures".
That is, just the opposite of the conventional anisostratal ML computer architecture, FvNA adopts the same instruction-set architecture (ISA) for every layer. "The lower layer is fully controlled by the higher layer, thus, only the top layer is exposed to the programmer as a monolithic processor. Therefore, ML computers built with FvNA are programmable under a scale-invariant, homogeneous, and sequential view," the researchers explained.
Although FvNA has been testified as applicable to the ML domain and capable of alleviating the programming productivity issue while functioning efficiently as its ad hoc counterparts, some problems remain to be solved. In this paper, the following three were addressed:
- How could FvNA remain quite efficient with such a strict architectural constraint?
- Is FvNA also applicable to payloads from other domains?
- If so, what are the exact prerequisites?
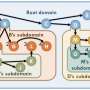
To answer these questions, the researchers started by modeling the fractal parallel machine (FPM), an abstract parallel computer modeled from FvNA. FPM was built on Valiant's multi-BSP, a homogeneous multilayered parallel model, with only minor extensions.
An instance of FPM is a tree structure of nested components; each component contains a memory, a processor, and child components. Components can execute fracops—the scheme of payloads on fractal parallel computing systems, such as reading some input data from the external storage, performing computation on the processor, and then writing output data to the external storage.
"Compared with Valiant's multi-BSP, FPM minimized the parameters for simpler abstraction," the researchers said. "What is more important, FPM puts explicit restrictions on the programming by only exposing a single processor to the programming interface. The processor is only aware of its parent component and child components, but not the global system specification." In other words, the program never knows where it resides in the tree structure. Therefore, FPM cannot be programmed to be scale-dependent by definition.
Meanwhile, the researchers proposed two different ML-targeting FvNA architectures—the specific Cambricon-F and the universal Cambricon-FR—and illustrated the fractal programming style of FPM by running several general-purpose sample programs. The samples covered embarrassingly parallel, divide-and-conquer, and dynamic programming algorithms, all of which were demonstrated as efficiently programmable.
"We clarified that, although originally developed from the domain of ML, fractal parallel computing is fairly generally applicable," the researchers concluded, drawing from their preliminary results that FPM, general-purpose and cost-optimal as it is, is as powerful as many fundamental parallel computing models such as BSP and alternating Turing machine. They also believed that full implementation of FPM could be handy in various scenarios, from the entire worldwide web to the micrometer-scale in vivo devices.
Still, the researchers pointed out a noteworthy discovery from this study that FPM limits the entropy of programming by applying constraints on the control pattern of the parallel computing systems. "Currently, fractal machines, such as Cambricon-F/FR, only leverage such entropy reduction to simplify software development," they observed. "Whether energy reduction can be achieved by introducing fractal controlling into conventional parallel machines is an interesting open question."
More information: Yongwei Zhao et al, Fractal Parallel Computing, Intelligent Computing (2022). DOI: 10.34133/2022/9797623