This article has been reviewed according to Science X's editorial process and policies. Editors have highlighted the following attributes while ensuring the content's credibility:
fact-checked
proofread
Content-oriented video anomaly detection using a self-attention–based deep learning model

Video anomaly detection, which differs from traditional video analysis, is a research hotspot in the field of computer vision, attracting many researchers. Usually, abnormal events occur only in a small percentage of the video pixels and therefore, it is unnecessary to focus on all the video pixels as most of them are harmless—called "the background."
Therefore, in the video feature extraction process, attention should be focused on a few detectable partial objects. Object detection is very complicated and consumes a significant amount of time during video processing. Therefore, it is not advisable to use object detection in the training phase to focus attention on the anomalous parts.
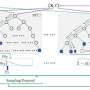
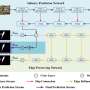
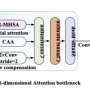
In a new paper published in Virtual Reality & Intelligent Hardware, a content-based video anomaly detection algorithm (COVAD) is proposed, and its network structure is modified based on the original memory-based video anomaly detection algorithm. The main goal of optimization in the training network is to focus on the objects in the video frame. The researchers used a content-based attention mechanism to optimize the structure of the encoding network and remove the last batch of the normalization layer of the U-Net network.
The former is used to focus on the target or content in the video and the latter is used to limit the powerful bias of the neural network because it is important to blur the boundary between normal and abnormal data in powerful representations. Compared with the object detection algorithm, the attention mechanism is lightweight, does not consume a lot of time, and can effectively process videos. The memory storage module stores more important content information than the entire video frame pixels. The experiments were deployed on the USCD and Avenue datasets, and the experimental results show that the proposed algorithm has better results than the benchmark models.
The main contributions of this paper are: 1) to propose a novel video anomaly detection method—called COVAD—for future frame prediction by combining the content-based attention mechanism, which can resist the interference of noise and focus on extracting the features of objects in the video; 2) to redefine the memory module that is used to classify and memorize various normal behavioral patterns available in video streams; and 3) to further improve the performance of video anomaly detection models focused on both normal and exceptional events.
The experimental results show that the performance of the proposed COVAD algorithm is significantly higher than that of the baseline models considered in this paper.
More information: Wenhao Shao et al, COVAD: Content-Oriented Video Anomaly Detection using a Self-Attention based Deep Learning Model, Virtual Reality & Intelligent Hardware (2023). DOI: 10.1016/j.vrih.2022.06.001