January 18, 2024 feature
This article has been reviewed according to Science X's editorial process and policies. Editors have highlighted the following attributes while ensuring the content's credibility:
fact-checked
peer-reviewed publication
trusted source
proofread
A simple technique to defend ChatGPT against jailbreak attacks
. DOI: 10.1038/s42256-023-00765-8.")
Large language models (LLMs), deep learning-based models trained to generate, summarize, translate and process written texts, have gained significant attention after the release of Open AI's conversational platform ChatGPT. While ChatGPT and similar platforms are now widely used for a wide range of applications, they could be vulnerable to a specific type of cyberattack producing biased, unreliable or even offensive responses.
Researchers at Hong Kong University of Science and Technology, University of Science and Technology of China, Tsinghua University and Microsoft Research Asia recently carried out a study investigating the potential impact of these attacks and techniques that could protect models against them. Their paper, published in Nature Machine Intelligence, introduces a new psychology-inspired technique that could help to protect ChatGPT and similar LLM-based conversational platforms from cyberattacks.
"ChatGPT is a societally impactful artificial intelligence tool with millions of users and integration into products such as Bing," Yueqi Xie, Jingwei Yi and their colleagues write in their paper. "However, the emergence of jailbreak attacks notably threatens its responsible and secure use. Jailbreak attacks use adversarial prompts to bypass ChatGPT's ethics safeguards and engender harmful responses."
The primary objective of the recent work by Xie, Yi and their colleagues was to highlight the impact that jailbreak attacks can have on ChatGPT and introduce viable defense strategies against these attacks. Jailbreak attacks essentially exploit the vulnerabilities of LLMs to bypass constraints set by developers and elicit model responses that would typically be restricted.
"This paper investigates the severe yet under-explored problems created by jailbreaks as well as potential defensive techniques," Xie, Yi and their colleagues explain in their paper. "We introduce a jailbreak dataset with various types of jailbreak prompts and malicious instructions."
The researchers first compiled a dataset including 580 examples of jailbreak prompts designed to bypass restrictions that prevent ChatGPT from providing answers deemed "immoral." This includes unreliable texts that could fuel misinformation as well as toxic or abusive content.
When they tested ChatGPT on these jailbreak prompts, they found that it often fell into their "trap," producing the malicious and unethical content they requested. Xie, Yi and their colleagues then set out to devise a simple and yet effective technique that could protect ChatGPT against carefully tailored jailbreak attacks.
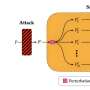
The technique they created draws inspiration from the psychological concept of self-reminders, nudges that can help people to remember tasks that they need to complete, events they are supposed to attend, and so on. The researchers' defense approach, called system-mode self-reminder, is similarly designed to remind Chat-GPT that the answers it provides should follow specific guidelines.
"This technique encapsulates the user's query in a system prompt that reminds ChatGPT to respond responsibly," the researchers write. "Experimental results demonstrate that self-reminders significantly reduce the success rate of jailbreak attacks against ChatGPT from 67.21% to 19.34%."
So far, the researchers tested the effectiveness of their technique using the dataset they created and found that it achieved promising results, reducing the success rate of attacks, although not preventing all of them. In the future, this new technique could be improved further to reduce the vulnerability of LLMs to these attacks, while also potentially inspiring the development of other similar defense strategies.
"Our work systematically documents the threats posed by jailbreak attacks, introduces and analyses a dataset for evaluating defensive interventions and proposes the psychologically inspired self-reminder technique that can efficiently and effectively mitigate against jailbreaks without further training," the researchers summarize in their paper.
More information: Yueqi Xie et al, Defending ChatGPT against jailbreak attack via self-reminders, Nature Machine Intelligence (2023). DOI: 10.1038/s42256-023-00765-8.
© 2024 Science X Network