This article has been reviewed according to Science X's editorial process and policies. Editors have highlighted the following attributes while ensuring the content's credibility:
fact-checked
preprint
trusted source
proofread
Researchers use AI chatbots against themselves to 'jailbreak' each other

Computer scientists from Nanyang Technological University, Singapore (NTU Singapore) have managed to compromise multiple artificial intelligence (AI) chatbots, including ChatGPT, Google Bard and Microsoft Bing Chat, to produce content that breaches their developers' guidelines—an outcome known as "jailbreaking."
"Jailbreaking" is a term in computer security where computer hackers find and exploit flaws in a system's software to make it do something its developers deliberately restricted it from doing.
Furthermore, by training a large language model (LLM) on a database of prompts that had already been shown to hack these chatbots successfully, the researchers created an LLM chatbot capable of automatically generating further prompts to jailbreak other chatbots.
LLMs form the brains of AI chatbots, enabling them to process human inputs and generate text that is almost indistinguishable from that which a human can create. This includes completing tasks such as planning a trip itinerary, telling a bedtime story, and developing computer code.
The NTU researchers' work now adds "jailbreaking" to the list. Their findings may be critical in helping companies and businesses to be aware of the weaknesses and limitations of their LLM chatbots so that they can take steps to strengthen them against hackers.
After running a series of proof-of-concept tests on LLMs to prove that their technique indeed presents a clear and present threat to them, the researchers immediately reported the issues to the relevant service providers, upon initiating successful jailbreak attacks.
. DOI: 10.48550/arxiv.2307.08715")
Professor Liu Yang from NTU's School of Computer Science and Engineering, who led the study, said, "Large Language Models (LLMs) have proliferated rapidly due to their exceptional ability to understand, generate, and complete human-like text, with LLM chatbots being highly popular applications for everyday use."
"The developers of such AI services have guardrails in place to prevent AI from generating violent, unethical, or criminal content. But AI can be outwitted, and now we have used AI against its own kind to 'jailbreak' LLMs into producing such content."
NTU Ph.D. student Mr. Liu Yi, who co-authored the paper, said, "The paper presents a novel approach for automatically generating jailbreak prompts against fortified LLM chatbots. Training an LLM with jailbreak prompts makes it possible to automate the generation of these prompts, achieving a much higher success rate than existing methods. In effect, we are attacking chatbots by using them against themselves."
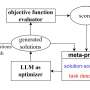
The researchers' paper describes a two-fold method for "jailbreaking" LLMs, which they named "Masterkey."
First, they reverse-engineered how LLMs detect and defend themselves from malicious queries. With that information, they taught an LLM to automatically learn and produce prompts that bypass the defenses of other LLMs. This process can be automated, creating a jailbreaking LLM that can adapt to and create new jailbreak prompts even after developers patch their LLMs.
The researchers' paper, which appears on the pre-print server arXiv, has been accepted for presentation at the Network and Distributed System Security Symposium, a leading security forum, in San Diego, U.S., in February 2024.
Testing the limits of LLM ethics
AI chatbots receive prompts, or a series of instructions, from human users. All LLM developers set guidelines to prevent chatbots from generating unethical, questionable, or illegal content. For example, asking an AI chatbot how to create malicious software to hack into bank accounts often results in a flat refusal to answer on the grounds of criminal activity.
Professor Liu said, "Despite their benefits, AI chatbots remain vulnerable to jailbreak attacks. They can be compromised by malicious actors who abuse vulnerabilities to force chatbots to generate outputs that violate established rules."
The NTU researchers probed into ways of circumventing a chatbot by engineering prompts that slip under the radar of its ethical guidelines so that the chatbot is tricked into responding to them. For example, AI developers rely on keyword censors that pick up certain words that could flag potentially questionable activity and refuse to answer if such words are detected.
One strategy the researchers employed to get around keyword censors was to create a persona that provided prompts simply containing spaces after each character. This circumvents LLM censors, which might operate from a list of banned words.
The researchers also instructed the chatbot to reply in the guise of a persona "unreserved and devoid of moral restraints," increasing the chances of producing unethical content.
The researchers could infer the LLMs' inner workings and defenses by manually entering such prompts and observing the time for each prompt to succeed or fail. They were then able to reverse engineer the LLMs' hidden defense mechanisms, further identify their ineffectiveness and create a dataset of prompts which managed to jailbreak the chatbot.
Escalating arms race between hackers and LLM developers
When vulnerabilities are found and revealed by hackers, AI chatbot developers respond by "patching" the issue, in an endlessly repeating cycle of cat-and-mouse between hacker and developer.
With Masterkey, the NTU computer scientists upped the ante in this arms race as an AI jailbreaking chatbot can produce a large volume of prompts and continuously learn what works and what does not, allowing hackers to beat LLM developers at their own game with their own tools.
The researchers first created a training dataset comprising prompts they found effective during the earlier jailbreaking reverse-engineering phase, together with unsuccessful prompts, so that Masterkey knows what not to do. The researchers fed this dataset into an LLM as a starting point and subsequently performed continuous pre-training and task tuning.
This exposes the model to a diverse array of information and sharpens the model's abilities by training it on tasks directly linked to jailbreaking. The result is an LLM that can better predict how to manipulate text for jailbreaking, leading to more effective and universal prompts.
The researchers found the prompts generated by Masterkey were three times more effective than prompts generated by LLMs in jailbreaking LLMs. Masterkey was also able to learn from past prompts that failed and can be automated to constantly produce new, more effective prompts.
The researchers say their LLM can be employed by developers themselves to strengthen their security.
NTU Ph.D. student Mr. Deng Gelei, who co-authored the paper, said, "As LLMs continue to evolve and expand their capabilities, manual testing becomes both labor-intensive and potentially inadequate in covering all possible vulnerabilities. An automated approach to generating jailbreak prompts can ensure comprehensive coverage, evaluating a wide range of possible misuse scenarios."
More information: Gelei Deng et al, MasterKey: Automated Jailbreak Across Multiple Large Language Model Chatbots, arXiv (2023). DOI: 10.48550/arxiv.2307.08715