October 31, 2014 weblog
Method to reconstruct overt and covert speech
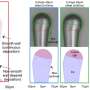
 The overt speech condition was used to train and test the accuracy of a neural-based decoding model to reconstruct spectrotemporal features of speech. The reconstructed patterns were compared to the true original (spoken out loud) speech representation (spectrogram or modulation-based). (B) During covert speech, there is no behavioral output, which prevents building a decoding model directly from covert speech data. Instead, the decoding model trained from the overt speech condition is used to decode covert speech neural activity. The covert speech reconstructed patterns were compared to identical speech segments spoken aloud during the overt speech condition (using dynamic time warping realignment). Credit: Front. Neuroeng., 27 May 2014. doi: 10.3389/fneng.2014.00014")
Can scientists read the mind, picking up inner thoughts? Interesting research has emerged in that direction. According to a report from New Scientist, researchers discuss their findings in converting brain activity into sounds and words. Their study, "Decoding spectrotemporal features of overt and covert speech from the human cortex," was published in Frontiers in Neuroengineering, an open-access academic publisher and research network.
To carry out their investigation, electrocorticographic (ECoG) recordings were obtained using subdural electrode arrays implanted in seven patients undergoing neurosurgical procedures for epilepsy. They first built a high gamma (70–150 Hz) neural decoding model to reconstruct spectrotemporal auditory features of self-generated overt speech. Then they evaluated whether this same model could reconstruct auditory speech features in the covert speech condition. Results provided evidence that auditory representations of covert speech can be reconstructed from models that are built from an overt speech data set. The recording session included text excerpts from historical political speeches or a children's story or Humpty Dumpty, visually displayed on the screen moving from right to left at the vertical center of the screen. "If you're reading text in a newspaper or a book, you hear a voice in your own head," said Brian Pasley at the University of California, Berkeley, in New Scientist. "We're trying to decode the brain activity related to that voice to create a medical prosthesis that can allow someone who is paralyzed or locked in to speak."
Helen Thomson in New Scientist explained further what the experiment was all about. "Each participant was asked to read the text aloud, read it silently in their head and then do nothing. While they read the text out loud, the team worked out which neurons were reacting to what aspects of speech and generated a personalized decoder to interpret this information. The decoder was used to create a spectrogram – a visual representation of the different frequencies of sound waves heard over time. As each frequency correlates to specific sounds in each word spoken, the spectrogram can be used to recreate what had been said. They then applied the decoder to the brain activity that occurred while the participants read the passages silently to themselves."
In the authors' Discussion section, they wrote that "Our results indicated that auditory features of covert speech could be decoded from models trained from an overt speech condition, providing evidence of a shared neural substrate for overt and covert speech. However, comparison of reconstruction accuracy in the two conditions also revealed important differences between overt and covert speech spectrotemporal representation."
The authors of the study are Stéphanie Martin, Peter Brunner, Chris Holdgraf, Hans-Jochen Heinze, Nathan E. Crone, Jochem Rieger, Gerwin Schalk, Robert T. Knight and Brian N. Pasley. Authors' institutional affiliations include University of California, Berkeley, École Polytechnique Fédérale de Lausanne, Switzerland, New York State Department of Health, Albany, Albany Medical College, Otto-von-Guericke-Universitat, Magdeburg, Germany, Johns Hopkins University, and Carl-von-Ossietzky University, Oldenburg, Germany.
Work continues. The team is fine-tuning their algorithms, said New Scientist, by looking at neural activity associated with speaking rate and different pronunciations of the same word, for example.
More information: Decoding spectrotemporal features of overt and covert speech from the human cortex, Front. Neuroeng., 27 May 2014. journal.frontiersin.org/Journa … neng.2014.00014/full
© 2014 Tech Xplore