May 8, 2017 report
Using deep learning to read images being processed in the brain

(Tech Xplore)—A team of researchers from several institutions in China has applied deep learning by a computer to the problem of reading visual imagery in the brain and then reproduced it in a 2-D format. A paper describing their project is available on the arXiv preprint server, describing their results and comparing them with other research efforts that attempt to achieve the same thing.
Imagine a machine that could look into your mind, see what you are seeing in real time, and then print out a picture of it. There are teams of researchers working on just that problem, and thus far, they have met with less than stellar results. Now, the group in China has found a way to solve at least one part of the problem by combining fMRI machines and deep learning algorithms.
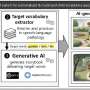
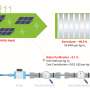
FMRI machines allow researchers to see which parts of the brain are activated by highlighting blood flow. Deep learning algorithms run on computers and learn how to do things by compiling many input examples and seeking patterns. In this new effort, the researchers combined the two technologies to capture three-dimensional arrays of neuronal activity (which they call voxels—a computer term for a type of three-dimensional modeling object) responding to visual stimuli, thus revealing what the eyes were seeing.
To capture data from the voxels, the researchers obtained 1,800 fMRI scans from a database used by prior researchers studying how the brain reacts to images of individual letters. The team fed 90 percent of the scans to the deep learning algorithm, which digested the information and looked for patterns in voxel location, shape, etc. Next, the team used the remaining 10 percent of the scans to test how well the system had learned to correctly identify voxels in the visual cortex and to recreate initial images which the system then printed.
The researchers report that their technique is the most accurate to date—an individual letter printed by the system looks very much like the original image the person was shown while under an fMRI machine. They offer photographic evidence of their results alongside both the original images and images made by researchers using other techniques.
More information: Sharing deep generative representation for perceived image reconstruction from human brain activity, arXiv:1704.07575 [cs.AI] arxiv.org/abs/1704.07575
Abstract
Decoding human brain activities via functional magnetic resonance imaging (fMRI) has gained increasing attention in recent years. While encouraging results have been reported in brain states classification tasks, reconstructing the details of human visual experience still remains difficult. Two main challenges that hinder the development of effective models are the perplexing fMRI measurement noise and the high dimensionality of limited data instances. Existing methods generally suffer from one or both of these issues and yield dissatisfactory results. In this paper, we tackle this problem by casting the reconstruction of visual stimulus as the Bayesian inference of missing view in a multiview latent variable model. Sharing a common latent representation, our joint generative model of external stimulus and brain response is not only "deep" in extracting nonlinear features from visual images, but also powerful in capturing correlations among voxel activities of fMRI recordings. The nonlinearity and deep structure endow our model with strong representation ability, while the correlations of voxel activities are critical for suppressing noise and improving prediction. We devise an efficient variational Bayesian method to infer the latent variables and the model parameters. To further improve the reconstruction accuracy, the latent representations of testing instances are enforced to be close to that of their neighbours from the training set via posterior regularization. Experiments on three fMRI recording datasets demonstrate that our approach can more accurately reconstruct visual stimuli.
© 2017 Tech Xplore