June 16, 2022 feature
A self-supervised model that can learn various effective dialog representations

Artificial intelligence (AI) and machine learning techniques have proved to be very promising for completing numerous tasks, including those that involve processing and generating language. Language-related machine learning models have enabled the creation of systems that can interact and converse with humans, including chatbots, smart assistants, and smart speakers.
To tackle dialog-oriented tasks, language models should be able to learn high-quality dialog representations. These are representations that summarize the different ideas expressed by two parties who are conversing about specific topics and how these dialogs are structured.
Researchers at Northwestern University and AWS AI Labs have recently developed a self-supervised learning model that can learn effective dialog representations for different types of dialogs. This model, introduced in a paper pre-published on arXiv, could be used to develop more versatile and better performing dialog systems using a limited amount of training data.
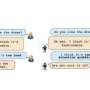
"We introduce dialog Sentence Embedding (DSE), a self-supervised contrastive learning method that learns effective dialog representations suitable for a wide range of dialog tasks," Zhihan Zhou, Dejiao Zhang, Wei Xiao, Nicholas Dingwall, Xiaofei Ma, Andrew Arnold, and Bing Xiang wrote in their paper. "DSE learns from dialogs by taking consecutive utterances of the same dialog as positive pairs for contrastive learning."
DSE, the self-supervised learning model developed by Zhou and his colleagues, draws inspiration from previous research efforts focusing on dialog models. As dialogs are essentially consecutive sentences or utterances that are semantically related to each other, the team developed a model that learns dialog representations by pairing consecutive utterances within the same dialog.
These pairs are used to train the model, via an approach known as contrastive learning. Contrastive learning is a self-supervised learning technique that uses augmentations of input data to devise several similar data representations.
"Despite its simplicity, DSE achieves significantly better representation capabilities than other dialog representation and universal sentence representation models," the researchers explained in their paper.
Zhou and his colleagues evaluated their model's performance on five different dialog tasks, each focusing on different semantic aspects of dialog representations. They then compared the model's performance to that of other existing approaches, including the TOD-BERT and SimCSE models.
"Experiments in few-shot and zero-shot settings show that DSE outperforms baselines by a large margin," the researchers wrote in their paper. "For example, it achieves 13% average performance improvement over the strongest unsupervised baseline in 1-shot intent classification on 6 datasets."
In initial tests, the new model for learning dialog representations attained a remarkable performance. In the future, it could thus be used to improve the performance of chatbots and other dialog systems.
In their paper, Zhou and his colleagues also outline their model's limitations and potential applications. Future works could continue perfecting their approach, to overcome some of its shortcomings.
"We believe DSE can serve as a drop-in replacement of the dialog representation model (e.g., the text encoder) for a wide range of dialog systems," the researchers added.
More information: Zhihan Zhou et al, Learning dialogue representations from consecutive utterances. arXiv:2205.13568v1 [cs.CL], arxiv.org/abs/2205.13568
© 2022 Science X Network