Finding the company (or companies) of peers

People at school, places of employment and many other settings often consider it worthwhile to find a group of peers to work or socialize with. But it can also be useful to organize companies into groups of peers, says Manish Singh, a Ph.D. student in the Department of Electrical Engineering and Computer Science. "Doing so can, for instance, help investors get a better sense of the market and enable government agencies to see how a particular sector of the economy is performing."
The practice of "industry peer grouping" has formally been going on since at least 1937, and several classification schemes are now in existence. One problem with the standard approaches to classification is that they've typically relied on just one source of information—such as written accounts of what a company does or a label that characterizes the general area in which a company's products and services lie. But now, with the advent of "Big Data," there are many more sources of information that one could potentially draw upon—such as a company's financials, news, stock returns, ESG (environmental, social, and governance) policies, and so forth. A new AI-based classification system—developed by researchers at MIT and the investment solutions provider MSCI—is designed to take information from multiple sources in order to find commonalities among companies. "That is the big difference between our system and more conventional approaches," Singh says.
Peter Zangari, MSCI's Global Head of Research and Product Development, agrees. "We're saying there are other factors in determining a peer group than what sector a particular company happens to be in," he maintains. "Our approach is much more general than that. We can basically make use of any electronically available piece of information that is recorded."
Industry peer grouping is important to asset managers, explains Zangari, "because when you are putting together an investment portfolio, you want to know which companies are similar, which are different, and how correlated they are to one another. If they're too highly correlated, the portfolio becomes undiversified, and that raises risk."
MIT's collaboration with MSCI started two years ago when MSCI recognized that their way of categorizing companies might benefit from the input of machine learning. In thinking about potential partners with expertise in that realm, company representatives met with Andrew W. Lo, the Charles E. and Susan T. Harris Professor and director of the Laboratory for Financial Engineering at the Sloan School of Management, and a research partnership was subsequently forged with an MIT group assembled by Lo. One result of this collaboration is the AI-driven Peer Grouping System (AIPGS), which is discussed in a paper that was published this spring in The Journal of Financial Data Science and reprinted on July 15, 2022.
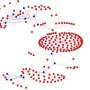
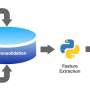
The AI component of AIPGS comes into play in several steps. The first step, according to Singh, involves "extracting features from the various data sets and converting those features into a form that can be used by our algorithms." Suppose, for example, there is a text document that describes what a company is doing. Natural language processing algorithms are then used so that a computer can interpret and understand the text. If there were 100 written descriptions, one round of analysis might determine how many of the words in one description also appear in other descriptions. A computer might also figure out which companies are mentioned together in the same news articles and how often that occurs. That information could be displayed on a graph—a mathematical object in which each company is represented by a node or vertex, and lines or "edges" are drawn between different nodes when companies are co-mentioned in the same article. An array of tools from network theory can then be applied to analyze the information encapsulated in this (graphical) form.
The next step, after all this information is fed to the algorithms, is to use machine learning techniques such as ridge regression—a methodology for learning relationships between two variables—in order to quantify the similarities between companies. This points to another advantage of AIPGS. Beyond just ascribing a common label to, say, 10 companies and telling you they all belong to the same group, as conventional methods typically do, Singh says, "our system can tell you the degree of similarity and actually rate them. Among the 10, which ones are most similar—or most dissimilar?"
Another attribute of AIPGS is that it can uncover, as the paper states, relationships and "groups that are not captured in existing classification systems… AIPGS also captured groupings that may seem unintuitive or surprising at first glance." In 2014, for example, the model lumped eBay with finance companies like Mastercard and Visa—a decision that might seem puzzling until one realizes that, at the time, eBay owned PayPal. In 2018, three years after eBay had split from PayPal, AIPGS placed it, more intuitively, in the e-commerce sector.
Sometimes the model finds correlations that are hard for an outside (human) observer to fathom. That can be seen as both a strength and weakness of the system, Singh says. It might be considered a strength simply because AI can, in the course of assimilating vast quantities of data, see things—and discern patterns—that are beyond the perceptive capacity of mortal beings. Making all of AIPGS' conclusions understandable would be a challenge, Singh adds. "Some of the tools in machine learning can be likened to a 'black box,' and some are not of that type. One approach would be to rely on AI methods that are more transparent—and not like a black box. We aim to explore the possibility of making models more transparent in the future."
More information: George Bonne et al, An Artificial Intelligence-Based Industry Peer Grouping System, The Journal of Financial Data Science (2022). DOI: 10.3905/jfds.2022.1.090