July 17, 2023 report
This article has been reviewed according to Science X's editorial process and policies. Editors have highlighted the following attributes while ensuring the content's credibility:
fact-checked
peer-reviewed publication
trusted source
proofread
Multiple 'selves' of modular agents boost AI learning

How and why we make thousands of decisions every day has long proven to be a popular area of research and commentary.
"Predictably Irrational: The Hidden Forces That Shape Our Decisions," by Dan Ariely; "Nudge: Improving Decisions about Health, Wealth and Happiness," by Richard Thaler and Cass Sunstein; and "Simply Rational: Decision Making in the Real World," by Gerd Gigerenzer, are just a few of the scores of books analyzing the mechanics of decision-making that appear on current best-seller lists.
A team of researchers at the Princeton Neuroscience Institute has now joined the discussion with a paper examining the decision-making process when it comes to machine learning. They say they have found an approach that improves upon the commonly applied single-agent process.
In a paper published July 3 in Proceedings of the National Academy of Sciences, researchers outlined a study comparing reinforcement learning approaches used in single AI agent and modular multi-AI agent systems.
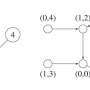
They trained deep reinforcement learning agents in a simple survival game on a two-dimensional grid. The agents were trained to seek various resources hidden around the field and to maintain sufficient supply levels to prevail.
One agent, seen as the "unified brain" or "self," operated in standard fashion, taking a step-by-step approach to evaluate each objective and, through trial-and-error, learning what the best solutions are each step of the way.
The modular agent, however, relied on input from sub-agents that had more narrowly defined goals and had their own unique experiences, successes and failures. Once input from the multiple modules were assessed in a single "brain," the agent made choices on how to proceed.
The researchers compared the setup to the principles involved in the classic longstanding debate over how the individual manages conflicting needs and objectives.
Whether a decision "relies on a single, monolithic agent (or 'self') that takes integrated account of all needs, or rather reflects an emergent process of competition among multiple modular agents (i.e., 'multiple selves') … pervades mythology and literature," lead researcher Jonathan Cohen said. "It is a focus of theoretical and empirical work in virtually every scientific discipline that studies agentic behavior, from neuroscience, psychology, economics, and sociology to artificial intelligence and machine learning."
The singular agent achieved the game's goals after 30,000 training steps. The modular agent, however, learned faster, making significant progress after only 5,000 learning steps.
"Compared to the standard monolithic approach, modular agents were much better at maintaining homeostasis of a set of internal variables in simulated environments, both static and changing," Cohen said.
The team concluded that the modular setup allowed sub-agents that focused on limited objectives to adapt to environmental challenges faster.
"The actions determined by the needs of one sub-agent served as a source of exploration for the others," Cohen said, "allowing them to discover the value of actions they may not have otherwise chosen in a given state."
He also explained that while the monolithic approach struggled with "the curse of dimensionality"—the exponentially spiraling growth of options as the complexity of the environment was increased—the modular agents, "specialists" with limited objectives, focused on smaller individual tasks and were better able to quickly adapt to environmental shifts.
"We show that designing an agent in a modular fashion as a collection of sub-agents, each dedicated to a separate need, powerfully enhanced the agent's capacity to satisfy its overall needs," the paper stated.
By more efficiently and more quickly adapting to changing environments and goals, researchers added, the modular approach "may also explain why humans have long been described as consisting of 'multiple selves.'"
More information: Zack Dulberg et al, Having multiple selves helps learning agents explore and adapt in complex changing worlds, Proceedings of the National Academy of Sciences (2023). DOI: 10.1073/pnas.2221180120
© 2023 Science X Network