May 22, 2024 feature
This article has been reviewed according to Science X's editorial process and policies. Editors have highlighted the following attributes while ensuring the content's credibility:
fact-checked
preprint
trusted source
proofread
A method to mitigate hallucinations in large language models
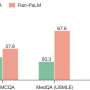
 and α = 0.05 (bottom) for score functions match count (m.c.), expected match count (e.m.c), and the log-probability (l.p.), and for various calibration methods (. denotes the baseline with no calibration). Box widths and heights represent 90% confidence intervals with Gaussian approximation over abstention rates and average test errors, respectively. The dashed horizontal line represents the target risk bound α. Credit: arXiv (2024). DOI: 10.48550/arxiv.2405.01563")
Large language models (LLMs), artificial neural networks-based architectures that can process, generate and manipulate texts in various human languages, have recently become increasingly widespread. These models are now being used in a wide range of settings, to rapidly find answers to queries, produce content for specific purposes and interpret complex texts.
While recently introduced LLMs can generate highly convincing texts, which are in some cases difficult to discern from writings produced by humans, they have been found to be prone to so-called hallucinations. In this context, hallucinations refer to an LLM generating entirely incoherent, inaccurate or inappropriate responses.
Researchers at DeepMind recently developed a new procedure that could help to identify instances in which LLM should refrain from responding to a query, for instance replying "I don't know," as they are likely to hallucinate non-sensical or incorrect answers. The team's proposed approach, outlined in a paper pre-published on arXiv, entails the use of LLMs to evaluate their own potential responses.
"Building on earlier approaches that use self-consistency as a more reliable measure of model confidence, we propose using the LLM itself to self-evaluate the similarity between each of its sampled responses for a given query," Yasin Abbasi Yadkori, Ilja Kuzborskij and their colleagues wrote in their paper. "We then further leverage conformal prediction techniques to develop an abstention procedure that benefits from rigorous theoretical guarantees on the hallucination rate (error rate)."
Yadkori, Kuzborskij and their colleagues evaluated their proposed method to mitigate LLM hallucinations in a series of experiments, using Temporal Sequences and TriviaQA, two publicly available datasets containing queries and associated responses. They specifically applied their proposed method to Gemini Pro, an LLM developed at Google and released in 2023.
"Experimentally, our resulting conformal abstention method reliably bounds the hallucination rate on various closed-book, open-domain generative question answering datasets, while also maintaining a significantly less conservative abstention rate on a dataset with long responses (Temporal Sequences) compared to baselines using log-probability scores to quantify uncertainty, while achieving comparable performance on a dataset with short answers (TriviaQA)," the researchers wrote.
"To evaluate the experiments automatically, one needs to determine if two responses are equivalent given a question. Following standard practice, we use a thresholded similarity function to determine if two responses match, but also provide a method for calibrating the threshold based on conformal prediction, with theoretical guarantees on the accuracy of the match prediction, which might be of independent interest."
The results of this research team's experiments suggest that their conformal calibration and similarity scoring procedure does mitigate LLM hallucinations, allowing a model to abstain from answering a question if their answer is likely to be non-sensical or untrustworthy. The newly proposed approach was found to outperform simple baseline scoring procedures.
This recent study by Deep Mind could soon inform the development of similar procedures to improve the reliability of LLMs and prevent them from hallucinating. Collectively, these efforts will contribute to the advancement of these models, facilitating their widespread use among professionals worldwide.
More information: Yasin Abbasi Yadkori et al, Mitigating LLM Hallucinations via Conformal Abstention, arXiv (2024). DOI: 10.48550/arxiv.2405.01563
© 2024 Science X Network