October 24, 2023 report
This article has been reviewed according to Science X's editorial process and policies. Editors have highlighted the following attributes while ensuring the content's credibility:
fact-checked
preprint
trusted source
proofread
Robots learn faster with AI boost from Eureka
. DOI: 10.48550/arxiv.2310.12931")
Intelligent robots are reshaping our universe. In New Jersey's Robert Wood Johnson University Hospital, AI-assisted robots are bringing a new level of security to doctors and patients by scanning every inch of the premises for harmful bacteria and viruses and disinfecting them with precise doses of germicidal ultraviolet light.
In agriculture, robotic arms driven by drones scan varying types of fruits and vegetables and determine when they are perfectly ripe for picking.
The Airspace Intelligence System AI Flyways takes over the challenging and often stressful tasks of flight dispatchers who must make last-minute flight pattern changes due to sudden extreme weather, depleted fuel supplies, mechanical problems or other emergencies. It optimizes solutions, is safer, saves time and is cost-efficient.
But forget about those accomplishments: Can a robot perform flawless pen-spinning tricks?
A team at NVIDIA Research developed one that can. And while the task is impressive—some experts say it could take months or even a year or more for humans to master the fine art of finger spinning, including challenging manipulations with names such as Devil's Sonic, Backaround, Corkscrew and Bust X2—what stands out about NVIDA's project is that the pen-spinning feat was taught by AI-generated instructions.
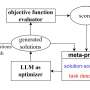
In a paper titled "Eureka: Human-Level Reward Design via Coding Large Language Models" that appears on the preprint server arXiv, researchers describe an "evolutionary optimization over reward code" in which robots learn complex fine-manipulation movements through AI generated instructions.
It holds the promise of ever-more efficient problem solving with LLMs, more advanced physical manipulation, and ever-smarter machines in our future.
The team developed Eureka, an algorithm applied to GPT-4 that establishes a reward system for LLMs learning advanced motor functions. The tasks are performed in a physical simulation application called Isaac Gym, developed by NVIDIA. Researchers from UPenn, Caltech and the University of Texas at Austin also participated in the project.
Results achieved through Eureka's training were superior to instructions designed by humans in 83% of the trials. The rapid pen-spinning task was one of 29 complex skills trained on the Eureka algorithm.
"The versatility and substantial performance gains of Eureka suggest that the simple principle of combining large language models with evolutionary algorithms is a general and scalable approach to reward design, an insight that may be generally applicable to difficult, open-ended search problems," said Anima Anandkumar, senior director of AI research at NVIDIA and an author of the Eureka paper.
The Isaac Gym simulates physical activity in a three-dimensional environment. The massively parallel training sessions rapidly generate possible solutions for numerous manipulations far faster than humans or early computation systems can. The gym, researchers say, can improve the speed of training by a factor of 1,000.
Feedback from human operators can be incorporated into training algorithms. The researchers say that would act as a "powerful co-pilot" in especially challenging tasks.
Other tasks accomplished through Eureka training include opening cabinets and drawers, handling scissors and tossing and catching balls.
Eureka compiles statistics of each session's progress and adjusts code to continually improve results.
According to Shital Shah, a principal research engineer at Microsoft Research, "The proverbial positive feedback loop of self-improvement might be just around the corner that allows us to go beyond human training data and capabilities."
More information: Yecheng Jason Ma et al, Eureka: Human-Level Reward Design via Coding Large Language Models, arXiv (2023). DOI: 10.48550/arxiv.2310.12931
Project website: eureka-research.github.io/
© 2023 Science X Network