This article has been reviewed according to Science X's editorial process and policies. Editors have highlighted the following attributes while ensuring the content's credibility:
fact-checked
preprint
trusted source
proofread
Novel AI framework generates images from nothing

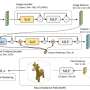
A new, potentially revolutionary artificial intelligence framework called "Blackout Diffusion" generates images from a completely empty picture, meaning that, unlike other generative diffusion models, the machine-learning algorithm does not require initiating a "random seed" to get started.
Blackout Diffusion, presented at the recent International Conference on Machine Learning, generates samples that are comparable to the current diffusion models, such as DALL-E or Midjourney but require fewer computational resources than these models.
"Generative modeling is bringing in the next industrial revolution with its capability to assist many tasks, such as generation of software code, legal documents, and even art," said Javier Santos, an AI researcher at Los Alamos National Laboratory and co-author of Blackout Diffusion.
"Generative modeling could be leveraged for making scientific discoveries, and our team's work laid down the foundation and practical algorithms for applying generative diffusion modeling to scientific problems that are not continuous in nature."
Diffusion models create samples similar to the data they are trained on. They work by taking an image and repeatedly adding noise until the image is unrecognizable. Throughout the process, the model tries to learn how to revert it back to its original state.
Current models require input noise, meaning they need some form of data to start producing images.
"We showed that the quality of samples generated by Blackout Diffusion is comparable to current models using a smaller computational space," said Yen-Ting Lin, the Los Alamos physicist who led the Blackout Diffusion collaboration.
Another unique aspect of Blackout Diffusion is the space it works in. Existing generative diffusion models work in continuous spaces, meaning the space they work in is dense and infinite. However, working in continuous spaces limits their potential for scientific applications.
"In order to run existing generative diffusion models, mathematically speaking, diffusion has to be living on a continuous domain; it cannot be discrete," Lin said.
On the other hand, the team's theoretical framework works in discrete spaces (meaning each point in the space is isolated from the others by some distance), which opens up opportunities for various applications, such as text and scientific applications.
The team tested Blackout Diffusion on a number of standardized datasets, including the Modified National Institute of Standards and Technology database; the CIFAR-10 dataset, which has images of objects in 10 different classes; and the CelebFaces Attributes Dataset, which consists of more than 200,000 images of human faces.
In addition, the team used the discrete nature of Blackout Diffusion to clarify several widely conceived misconceptions about how diffusion models internally, providing a critical understanding of generative diffusion models.
They also provide design principles for future scientific applications. "This demonstrates the first foundational study on discrete-state diffusion modeling and points the way toward future scientific applications with discrete data," Lin said.
The team explains that generative diffusion modeling can potentially drastically speed up the time spent running many scientific simulations on supercomputers, which would both support scientific progress and reduce the carbon footprint of computational science. Some of the diverse examples they mention are subsurface reservoir dynamics, chemical models for drug discovery, and single-molecule and single-cell gene expression for understanding biochemical mechanisms in living organisms.
The study is published on the arXiv preprint server.
More information: Javier E Santos et al, Blackout Diffusion: Generative Diffusion Models in Discrete-State Spaces, arXiv (2023). DOI: 10.48550/arxiv.2305.11089