October 19, 2023 feature
This article has been reviewed according to Science X's editorial process and policies. Editors have highlighted the following attributes while ensuring the content's credibility:
fact-checked
preprint
trusted source
proofread
A Hebbian memory that achieves human-like results on sequential processing tasks

Transformers are machine learning models designed to uncover and track patterns in sequential data, such as text sequences. In recent years, these models have become increasingly sophisticated, forming the backbone of popular conversational platforms, such as ChatGPT,
While existing transformers have achieved good results in a variety of tasks, their performance often declines significantly when processing longer sequences. This is due to their limited storage capacity, or in other words the small amount of data they can store and analyze at once.
Researchers at Sungkyunkwan University in South Korea recently developed a new memory system that could help to improve the performance of transformers on more complex tasks characterized by longer data sequences. This system, introduced in a paper published on the arXiv preprint server, is inspired by a prominent theory of human memory, known as Hebbian theory.
"Transformers struggle with long input sequences due to their limited capacity," Sangjun Park and JinYeong Bak wrote in their paper. "While one solution is to increase input length, endlessly stretching the length is unrealistic. Furthermore, humans selectively remember and use only relevant information from inputs, unlike transformers which process all raw data from start to end."
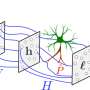
The primary objective of the recent work by Park, Bak and their colleagues was to design a system that could advance the capabilities of transformer models, utilizing a well-established neuropsychological theory. This theory, known as Hebbian theory, essentially suggests that neurons and cells that are repeatedly activated together tend to become associated, with these associations ultimately leading to learning.
"We introduce Memoria, a general memory network that applies Hebbian theory which is a major theory explaining human memory formulation to enhance long-term dependencies in neural networks," Park and Bak explain in their paper. "Memoria stores and retrieves information called engram at multiple memory levels of working memory, short-term memory, and long-term memory, using connection weights that change according to Hebb's rule."
So far, the researchers evaluated their Hebbian memory system in a series of experiments, attaining very promising results. Memoria was found to significantly enhance the performance of transformers in a variety of tasks involving the processing of long data sequences.
"Through experiments with popular transformer-based models like BERT and GPT, we present that Memoria significantly improves the ability to consider long-term dependencies in various tasks," the researchers wrote in their paper. "Results show that Memoria outperformed existing methodologies in sorting and language modeling, and long text classification."
The promising memory architecture developed by these researchers could soon be tested on a broader range of complex tasks, to further explore its potential. In addition, other research groups worldwide could soon start using it to boost the performance of their transformer-based models.
The code written by Park and Bak is open-source and can be readily accessed on GitHub. As part of their study, the researchers deployed Memoria using an independent Python package, which further facilitates its use by developers worldwide.
More information: Sangjun Park et al, Memoria: Hebbian Memory Architecture for Human-Like Sequential Processing, arXiv (2023). DOI: 10.48550/arxiv.2310.03052
© 2023 Science X Network